
The field of artificial intelligence (AI) is experiencing a transformative shift, driven by the rise of open-source large language models (LLMs). These foundation models serve as the backbone for various advanced applications, enabling innovations in fields such as generative AI and tailored assistants. These models, freely available on platforms like GitHub and Hugging Face, are reshaping how engineers approach AI development by reducing barriers to entry and enabling faster innovation. In the past, access to sophisticated AI models required significant resources, both in terms of data and infrastructure. Today, thanks to advancements in model architectures—most notably transformers—and new training techniques like self-supervised learning (SSL), LLMs have become accessible to a wide range of businesses and developers.
Transformers have revolutionized the landscape with their ability to handle vast amounts of data while maintaining high accuracy. Self-supervised learning, which trains models using massive amounts of unlabeled data, has made these models not only more adaptable but also more efficient. These technological advances have democratized AI, making it easier for engineers to integrate LLMs into various production environments and offering solutions that were previously only possible for large-scale tech firms.
For engineers, the ability to experiment with and deploy open-source LLMs quickly and cost-effectively is a game-changer. With repositories like Hugging Face providing access to pre-trained models and tools for fine-tuning, engineers can adapt these powerful models to specific business needs, driving innovation in sectors ranging from customer service to healthcare and beyond. The shift toward open-source LLMs has paved the way for a new era of AI development, where accessibility, scalability, and technical performance converge, enabling engineers to build smarter, more efficient systems.
This introduction sets the stage for a deeper exploration of how these technologies are reshaping the world of engineering, highlighting the practical benefits and challenges engineers face when working with open-source LLMs.
Open-source large language models (LLMs) have revolutionized the field of artificial intelligence, enabling developers and researchers to access and contribute to advanced language models. These models are designed to understand, generate, and manipulate human language, making them a crucial component of various applications, including chatbots, language translation, and text summarization. By leveraging the power of open-source LLMs, engineers can build sophisticated AI tools that can process and interpret human language with remarkable accuracy and efficiency.
What is an open-source LLM?
An open-source LLM is a type of artificial intelligence model that is freely available for use, modification, and distribution. These models are typically developed and maintained by a community of researchers and developers, who contribute to their development and improvement. Open-source LLMs are often released under permissive licenses, such as Apache 2.0, which allows users to modify and distribute the models without restrictions. This collaborative approach fosters innovation and accelerates the advancement of AI technologies, making cutting-edge language models accessible to a broader audience.
Benefits of open-source LLMs
Open-source LLMs offer several benefits, including:
-
Cost-effectiveness: Open-source LLMs are free to use and modify, reducing the costs associated with developing and maintaining proprietary models. This makes advanced AI capabilities accessible to startups and smaller organizations that may not have the resources to invest in proprietary solutions.
-
Flexibility: Open-source LLMs can be modified and customized to suit specific use cases and applications. Engineers can fine-tune these models to address unique business needs, ensuring optimal performance for their particular tasks.
-
Community involvement: Open-source LLMs are developed and maintained by a community of researchers and developers, who contribute to their improvement and development. This collaborative environment encourages knowledge sharing and continuous enhancement of the models.
-
Transparency: Open-source LLMs provide transparency into their development and training data, enabling users to understand how the models work and make informed decisions. This transparency is crucial for building trust and ensuring the ethical use of AI technologies.
LLM Architecture and Model Engineering
Large Language Models (LLMs) like GPT-based and T5 architectures have transformed natural language processing. These models are built on transformer architectures, which employ self-attention mechanisms and performance optimized layer implementations to efficiently process data across long sequences. Key to their success is the multi-layered structure—where layers are stacked to capture increasingly abstract representations of text data.
Training these models requires immense computational power, often leveraging gradient-based optimization and distributed training techniques. A significant challenge is balancing performance with computational cost, as noted by Cornell researchers who emphasize the growing limits of high-quality training data availability.
Open-source platforms like Hugging Face and GitHub repositories enable developers to build on pre-trained models, reducing the need to start from scratch. However, scaling these models requires addressing problems such as data sparsity and overfitting, making model fine-tuning essential for specific tasks.
As a result, engineers face the dual challenge of maintaining model performance while ensuring scalable, cost-efficient deployment. The adoption of frameworks like PyTorch and TensorFlow, alongside attention optimization techniques (e.g., cross-attention), has made scalable model engineering more feasible.
Choosing the Right Open-Source LLM
With the increasing number of open-source LLMs available, choosing the right model for a specific use case can be challenging. Here are some factors to consider when selecting an open-source LLM:
-
Performance: Evaluate the model’s performance on various benchmarks and tasks to ensure it meets your requirements. Look for models that have demonstrated high accuracy and efficiency in similar applications.
-
Training data: Consider the quality and diversity of the training data used to develop the model. High-quality training data is essential for producing reliable and robust language models.
-
License: Ensure the model is released under a permissive license that allows for modification and distribution. Licenses like Apache 2.0 provide the flexibility needed for customization and integration into different projects.
-
Community support: Evaluate the level of community support and involvement in the model’s development and maintenance. A strong community can provide valuable resources, updates, and troubleshooting assistance.
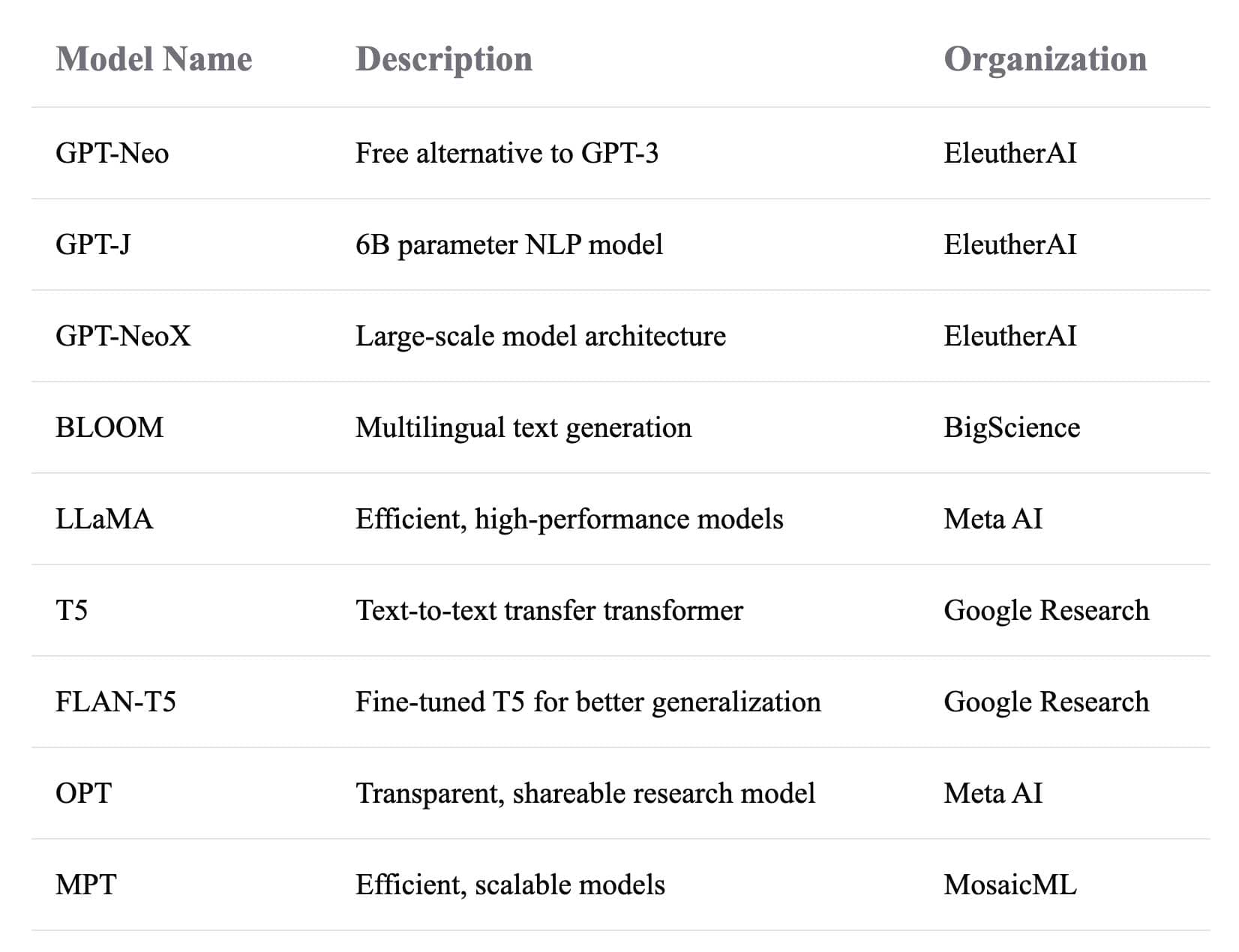
Popular open-source LLMs
Here are some popular open-source LLMs:
-
LLaMA: Developed by Meta AI, LLaMA is a high-performance large language model designed for research purposes. It is known for its efficiency and adaptability in various applications, including natural language understanding and translation.
-
Opt: Developed by Meta AI, OPT (Open Pretrained Transformer) is an open-source large language model designed to promote transparency and accessibility in AI research and development. It aims to provide a scalable and efficient foundation for various natural language processing tasks, suitable for both research and practical applications.
-
Bloom: Developed by the BigScience project, Bloom is an open-access, multilingual large language model designed for efficient language processing and understanding. It excels in tasks like content generation and multilingual translation.
-
T5: Developed by Google, T5 is a popular large language model known for its text-to-text framework, making it highly adaptable for a range of tasks, including translation and summarization.
These models are widely used and have been evaluated on various benchmarks, making them a good starting point for developers and researchers looking to explore open-source LLMs. By selecting the right model, engineers can leverage the power of large language models to create innovative and effective AI solutions.
Setting Up LLMs in Production Environments
Deploying large language models (LLMs) into production requires integrating them with frameworks like PyTorch, TensorFlow, or Hugging Face’s transformers. When deploying LLMs, managing private data securely is crucial, especially when fine-tuning models on personal datasets within a user's own cloud account. Hugging Face has become the industry standard for integrating pre-trained models into existing systems, simplifying tasks such as model loading and inference optimization. For containerization, using tools like Docker to encapsulate models and Kubernetes for orchestration is essential to ensure scalability and resource management. Kubernetes manages resources by dynamically scaling deployments based on demand, optimizing the use of GPUs or TPUs in distributed systems.
In real-world scenarios, engineers are challenged with balancing model performance and cost efficiency. One example involves deploying LLMs with containerized microservices, where each model operates independently, ensuring modularity and allowing teams to roll out updates without disrupting the entire system. Hugging Face transformers’ integration with APIs makes the process even more streamlined. Techniques like model pruning and quantization can further enhance performance while managing hardware limitations.
Additionally, resource monitoring becomes crucial in production, where cloud providers like AWS or GCP can be utilized for scaling resources dynamically based on traffic. Open-source LLMs can be deployed across both cloud and on-premise environments using these containerized and orchestrated frameworks, offering flexibility to engineers aiming to optimize for both performance and cost-efficiency.
Optimizing Performance – Hardware, Fine-Tuning, Training Data, and Inference
Optimizing the performance of large language models (LLMs) in production environments requires a multi-faceted approach, combining hardware acceleration, fine-tuning techniques, and inference optimization. Leveraging GPUs and TPUs is critical for high-throughput, low-latency inference, with cloud platforms providing infrastructure tailored for LLM workloads. Techniques such as model fine-tuning allow engineers to adapt a base model to specific tasks, improving accuracy while reducing computational overhead.
Quantization, which involves reducing the precision of model weights (e.g., from 32-bit to 8-bit), is another practical optimization for reducing model size without significantly impacting performance. Techniques like static kv-cache for memory efficiency and speculative decoding for faster outputs are essential for effective performance management. Pruning, which removes redundant neurons or weights, further streamlines models, ensuring more efficient resource usage during inference.
Finally, real-time performance gains are achieved by optimizing the attention mechanisms, particularly in transformer models. Tools improve the computational efficiency of attention layers, significantly cutting down inference time while maintaining accuracy.
In practice, NVIDIA’s CUDA and TensorRT libraries are commonly used to enhance LLM performance on GPUs, enabling faster deployment in high-demand environments. These optimizations, when combined with resource management solutions like Kubernetes for scalability, ensure that even the most computationally intensive models can operate effectively in production environments.
Real-Time Applications – Case Studies and Best Practices
As large language models (LLMs) continue to revolutionize various industries, real-time applications of these models have become increasingly important in sectors such as healthcare, finance, and customer service. These models are designed for both research and commercial use, making them versatile tools for a wide range of applications. Deploying LLMs in real-time environments, where latency, scalability, and reliability are crucial, poses unique challenges. In this section, we explore practical examples of LLM deployments in these industries and provide actionable insights and tools that engineers can use to meet real-time requirements.
1. Healthcare: Enhancing Diagnostics with Real-Time LLMs
In healthcare, LLMs are being leveraged to support doctors in diagnostics, patient data management, and clinical decision-making. Institutions like the Technology Innovation Institute are at the forefront of developing advanced models that enhance diagnostics and patient care. These systems ensure rapid inference and low-latency responses, critical in situations where time-sensitive decisions are needed.
Actionable Insight: Engineers aiming to deploy real-time LLMs in healthcare must prioritize response time and ensure model accuracy to prevent misdiagnosis. Using frameworks like ONNX can help by converting models to a more efficient format, optimized for hardware accelerators like GPUs and TPUs. FastAPI is a lightweight web framework that supports asynchronous processing, enabling engineers to serve LLM predictions swiftly in real-time applications.
2. Finance: Real-Time Fraud Detection and Risk Management
The finance industry heavily depends on real-time LLM deployments to manage fraud detection and risk analysis. Large financial institutions are now deploying LLMs for real-time transaction monitoring, using systems that flag suspicious behavior based on vast data inputs processed in milliseconds. These systems need to process multiple transactions simultaneously, requiring optimized model inference and scalable infrastructure.
For example, many companies use hardware accelerators like TPUs or GPUs to handle large-scale, low-latency fraud detection tasks, ensuring that even complex transactions are processed in real time.
Actionable Insight: For engineers deploying LLMs in finance, the use of hardware accelerators like TPUs or GPUs is essential to meet the industry's demanding real-time requirements. Furthermore, combining Kubernetes for containerized microservices and ONNX for optimized model inference can ensure that models scale effectively while maintaining low latency.
3. Customer Service: Scaling Personalized Interactions with LLMs
Customer service platforms are increasingly turning to LLMs to handle real-time chatbots and virtual assistants, allowing businesses to provide instant, personalized responses to customer queries. Hugging Face's open-source tools have enabled companies to deploy fine-tuned LLMs that adapt to various customer needs. These chatbots are often built with frameworks like FastAPI for lightweight, fast APIs.
For instance, many companies are deploying chatbots using LLMs on Kubernetes, allowing systems to scale during peak times. By using quantization techniques, they reduce the size of their models, ensuring faster response times without sacrificing accuracy.
Actionable Insight: Engineers developing real-time customer service LLMs should leverage quantization and other optimization techniques to reduce model size and inference time. Combining FastAPI with Kubernetes enables scalable, low-latency deployments, making these solutions practical even during periods of high traffic.
Key Tools for Real-Time LLM Deployments
-
FastAPI: A high-performance web framework for building APIs quickly, supporting asynchronous tasks for faster model responses.
-
ONNX Runtime: Converts models into an optimized format, allowing for cross-platform deployment with accelerated inference using hardware like GPUs and TPUs.
-
Kubernetes: Ideal for deploying and scaling LLM-based microservices in a real-time environment, offering automated load balancing and fault tolerance.
-
TPUs and GPUs: Hardware accelerators that significantly reduce inference time, essential for real-time LLM deployments.
Real-time deployments of LLMs are transforming industries by enabling faster, more accurate responses in critical applications. Engineers can enhance the performance of these systems through tools like FastAPI, ONNX Runtime, and Kubernetes, and by leveraging hardware accelerators. Whether in healthcare, finance, or customer service, understanding the right mix of software and hardware is key to creating reliable, real-time LLM applications.
Future Trends in Open-Source: Open Source LLMs and Engineering Challenges
The future of open-source large language models (LLMs) is filled with promise, as these models represent the cutting edge of AI technology, yet it also presents significant engineering challenges. As LLMs continue to evolve, several key trends will shape the landscape, including advances in model scaling, distributed training, and the integration of multi-modal capabilities. However, these innovations bring forth critical issues related to sustainability in computing power and the ethical use of AI.
1. Emerging Trends in LLM Scaling
Distributed Training: One of the most prominent trends in the future of LLMs is distributed training, where model training is spread across multiple GPUs or TPUs, either in data centers or on cloud platforms. This approach enables engineers to train massive models more efficiently, reducing training time and improving scalability. Tools like Hugging Face’s Transformers library and Google Cloud’s TPU support have made this technology more accessible to the engineering community. Distributed training frameworks like Ray and Kubernetes are essential in managing large-scale computations across diverse infrastructure.
Multi-Modal Models: Another significant trend is the integration of multi-modal models, which can process different types of data simultaneously, such as text, images, and audio. Advanced LLMs are also making strides in code generation, automating coding tasks and increasing developer productivity. These models open new doors for applications in industries like healthcare, where models can analyze medical images and patient data together, or in retail, where customer sentiment from text and visual cues can be processed in real time. Multi-modal LLMs require more sophisticated training pipelines, often incorporating multiple datasets and different types of input, posing unique challenges in terms of data handling and model optimization.
2. Sustainability and Computing Power
As LLMs scale, their energy consumption becomes a pressing concern. The training of large models can have a significant carbon footprint, leading to a growing emphasis on sustainable AI. There is increasing pressure on AI developers to reduce energy consumption during model training and inference. Techniques such as model quantization, pruning, and efficient model architectures are critical in reducing the environmental impact without sacrificing performance. In practice, companies and engineers are looking toward hardware accelerators like NVIDIA's GPUs and Google's TPUs to optimize performance while managing energy use.
Moreover, there is a movement toward “green AI” initiatives, focusing on making AI development more energy-efficient. Engineers need to consider not only the accuracy and scalability of their models but also their long-term sustainability. This trend could lead to the adoption of newer frameworks and techniques that prioritize both computational efficiency and environmental responsibility.
3. Ethical Considerations in Open-Source LLM Development
The ethical use of LLMs is another crucial area that will shape the future of this technology. As open-source LLMs become more prevalent, ensuring fairness, transparency, and security in AI applications becomes increasingly challenging. One of the primary concerns is bias in LLMs, which can arise from the training data used. LLMs are trained on vast datasets from the internet, which can contain biased, unfiltered, or harmful content. Engineers must implement techniques like data filtering and fairness auditing to mitigate these issues.
Additionally, the open-source nature of many LLMs means that bad actors can potentially use these models for malicious purposes, such as generating misinformation or deepfakes. Therefore, building safeguards into the deployment process—whether through API restrictions, licensing agreements, or ethical guidelines—will be a key consideration moving forward.
Future Engineering Challenges
Engineers developing and deploying open-source LLMs will face several core challenges in the coming years:
-
Resource Management: As LLMs grow in size, engineers must balance the need for computational resources with performance requirements. Distributed computing frameworks like Kubernetes are critical, but managing resources across large-scale deployments will continue to be a challenge.
-
Model Fine-Tuning and Adaptation: Fine-tuning large models to adapt to specific tasks without excessive computational cost will remain a priority. Engineers will need to explore advanced optimization techniques, such as parameter-efficient transfer learning and hybrid training methods, to ensure models can scale while remaining adaptable.
-
Security and Privacy: Data privacy and security are essential when deploying LLMs in sensitive sectors like healthcare and finance. Techniques like differential privacy and encrypted model inference will be increasingly important as the use of LLMs expands into domains requiring strict confidentiality.
Conclusion
The future of open-source LLMs is both exciting and challenging. As these models continue to scale and integrate new capabilities like multi-modal processing, engineers must tackle the technical hurdles of distributed training, resource optimization, and sustainability. At the same time, ethical considerations such as bias, transparency, and security will shape how these models are developed and deployed. Engineers who stay at the forefront of these trends will be best positioned to leverage the power of LLMs while ensuring their responsible and sustainable use in real-world applications.
References
- DataCamp | Top Open Source LLMs
- Hugging Face | Transformers Documentation: LLM Optimizations
- Google Cloud | Accelerating AI Inference with Google Cloud TPUs and GPUs
- Hugging Face | Open LLM Leaderboard
- Giselles.ai | Multimodal AI Interfaces
- Giselles.ai | ETL AI & ML Pipelines
- Giselles.ai | Unlocking the Future of Personal Finance with AI: How Generative AI Are Reshaping Money Management
- Giselles.ai | AI in healthcare: Navigating Challenges and Transforming Medicine
Please Note: This content was created with AI assistance. While we strive for accuracy, the information provided may not always be current or complete. We periodically update our articles, but recent developments may not be reflected immediately. This material is intended for general informational purposes and should not be considered as professional advice. We do not assume liability for any inaccuracies or omissions. For critical matters, please consult authoritative sources or relevant experts. We appreciate your understanding.