1. Introduction to Language Models
Large Language Models (LLMs) have emerged as one of the most transformative innovations in artificial intelligence (AI). Their ability to process, understand, and generate human language at a near-human level has opened up new possibilities across industries, making large language models important for various applications. From chatbots that provide personalized customer service to AI systems that assist in medical diagnoses, LLMs are reshaping the way we interact with technology and information.
In this article, we will explore the core aspects of LLMs, how they work, and their wide-ranging applications. We will also dive into the benefits they offer, such as enhancing productivity and natural language understanding, while discussing the challenges they pose, including ethical considerations and data privacy concerns. The quality of datasets used for training these models is crucial, as it directly impacts the language model's performance. By the end, you will have a comprehensive understanding of large language models and the immense potential they hold for future innovation.
The Rise of LLMs
The journey of LLMs began with significant breakthroughs in natural language processing (NLP) and machine learning, primarily driven by advancements in neural networks and deep learning architectures. Unlike traditional AI systems, which relied on pre-programmed rules to understand and respond to language, LLMs can learn from vast datasets and adapt to a wide range of linguistic tasks. Large language models work by undergoing extensive training processes that involve unsupervised learning, word embeddings, and fine-tuning techniques to optimize performance for specific tasks. This adaptability has made them invaluable in applications such as search engines, content generation, translation, and even creative writing.
Today, LLMs are a key component of various AI-driven services and platforms. For instance, virtual assistants like Siri and Alexa rely on LLMs to understand and respond to complex user queries. Content recommendation engines use them to analyze text and provide personalized suggestions, and advanced chatbots leverage them to engage users in natural and meaningful conversations.
The Basics of Language Models
Language models are a cornerstone of artificial intelligence (AI) designed to process and understand human language. These models are trained on vast amounts of text data, enabling them to learn the intricate patterns, relationships, and structures inherent in language. This training allows language models to perform a variety of natural language processing (NLP) tasks, such as language translation, text summarization, and sentiment analysis.
At their core, language models are statistical tools that predict the probability of a word or a sequence of words occurring in a given context. They achieve this by analyzing the relationships between words, phrases, and sentences to generate coherent and meaningful text. Language models can be broadly categorized into two main types: statistical language models and neural language models.
Statistical language models, such as n-gram models and hidden Markov models, use statistical techniques to predict the likelihood of word sequences. While these models are simple and efficient, they often struggle with capturing complex language structures and nuances.
Neural language models, on the other hand, leverage neural networks to learn language patterns and relationships. These models are more powerful and flexible than their statistical counterparts, capable of handling the complexities and subtleties of human language. Neural language models form the foundation of modern NLP and are widely used in applications ranging from language translation and text summarization to chatbots and virtual assistants.
2. Understanding Large Language Models
What is a Large Language Model?
A Large Language Model (LLM) is an advanced type of artificial intelligence designed to understand, process, and generate human language with remarkable accuracy and fluency. LLMs are built using vast amounts of data and leverage deep learning techniques to perform a variety of tasks, such as text generation, translation, summarization, and answering questions. Unlike traditional models that relied on rule-based systems, LLMs use neural networks to learn language patterns, making them adaptable to diverse tasks and improving their ability to generate contextually relevant responses.
At their core, LLMs function as large scale models built using extensive datasets and deep learning techniques. These models analyze patterns within large datasets, identifying relationships between words, phrases, and concepts. This ability allows them to perform complex natural language processing tasks that closely resemble human language understanding. The key distinguishing factor of LLMs is their size—measured in billions or even trillions of parameters, which are adjustable variables within the model that the AI uses to predict and generate text. These massive models outperform earlier AI systems in versatility, accuracy, and language comprehension.
Evolution of LLMs
The development of Large Language Models marks a significant advancement in the history of natural language processing (NLP). Early NLP systems primarily relied on rule-based methods and statistical models to understand and generate text. These systems were limited in their ability to handle context, ambiguity, and the complexities of human language. The introduction of machine learning and deep learning opened the door to more sophisticated models, leading to significant improvements in language comprehension.
The evolution of LLMs can be traced back to the introduction of neural networks and deep learning architectures. Early breakthroughs, such as recurrent neural networks (RNNs) and long short-term memory networks (LSTMs), improved the ability of machines to retain context over longer sequences of text. However, it was the introduction of the Transformer architecture in 2017 that truly revolutionized the field. Transformers allowed models to process text in parallel, leading to faster and more efficient training on massive datasets. This breakthrough paved the way for the development of today's most advanced LLMs, which are now capable of generating coherent, context-aware text across a wide range of applications.
The Science Behind LLMs
At the heart of Large Language Models lies a powerful combination of deep learning, neural networks, and the Transformer architecture. These models are typically trained on billions of words sourced from diverse datasets, including books, websites, and other forms of text. The sheer scale of the data allows LLMs to learn intricate language patterns, idioms, and cultural references, enabling them to generate text that appears naturally fluent and human-like.
The Transformer architecture, introduced in the seminal paper “Attention is All You Need,” is the backbone of modern LLMs. The transformer model includes an encoder and decoder structure, leveraging self-attention mechanisms to understand context and relationships in language, ultimately enabling faster learning and superior performance in processing sequential data. This differs from previous models, such as RNNs, which processed text sequentially, often leading to difficulties in handling long-range dependencies.
The training process of an LLM involves two key stages: pre-training and fine-tuning. During pre-training, the model is exposed to vast amounts of text and learns to predict the next word in a sentence based on the context of preceding words. This stage equips the model with a broad understanding of language. Fine-tuning, on the other hand, involves training the pre-trained model on smaller, domain-specific datasets to tailor its performance to particular tasks, such as answering customer queries or summarizing legal documents.
The size of an LLM is measured by its number of parameters—the elements within the model that are adjusted during training to optimize performance. Larger models, with more parameters, tend to perform better on complex tasks, but they also require significantly more computational resources for training and deployment. While early LLMs contained hundreds of millions of parameters, today’s leading models often contain tens or hundreds of billions, demonstrating the exponential growth in the field. Very large models, however, come with significant resource requirements, training challenges, and potential biases, necessitating careful engineering and ethical considerations.
Core Advancements from Transformers to LLMs
The journey from the foundational Transformer model to advanced Large Language Models (LLMs) marks a significant evolution in natural language processing (NLP) and beyond. Initially developed as an efficient solution for sequence-to-sequence tasks, the Transformer architecture introduced core innovations that laid the groundwork for the development of LLMs. These advances include self-attention mechanisms, parallelized processing of entire sequences, and the ability to capture long-range dependencies across input data.
-
Self-Attention and Multi-Head Attention: The self-attention mechanism, a defining feature of Transformers, enables the model to focus on different parts of a sentence, irrespective of token position. Multi-head attention further enhances this by allowing the model to consider multiple relational aspects simultaneously, thereby understanding complex sentence structures and nuances. This ability to dynamically assign importance to various words in a sequence was crucial for transitioning from simple sequence models to more sophisticated language models like GPT and BERT.
-
Scalability with Parallelization: Unlike Recurrent Neural Networks (RNNs) that process tokens sequentially, Transformers handle entire sequences in parallel, which significantly accelerates training. This parallelization allows LLMs to scale to billions or even trillions of parameters, making them capable of processing vast datasets efficiently. This scaling is pivotal for training large models on comprehensive datasets, as seen in OpenAI’s GPT-3 and similar LLMs.
-
Pre-training and Fine-Tuning Framework: Transformers’ architecture supports a two-stage training approach: pre-training on large, unsupervised datasets to capture general language patterns, followed by fine-tuning on specific tasks or domains. This approach enables LLMs to achieve state-of-the-art performance across a wide range of applications, from text completion to question answering. Fine-tuning further allows LLMs to specialize, making them adaptable to niche applications like medical diagnosis or legal analysis.
Expanding the Transformer Model’s Capabilities
Transformers are no longer limited to text-based applications. Extensions of the model architecture have enabled their use in various fields, demonstrating remarkable flexibility:
-
Vision and Image Generation: Transformers can be applied to image classification and generation tasks by treating images as sequences of patches. For instance, Vision Transformers (ViTs) have shown impressive results in image classification, while generative models like DALL-E use Transformer-based architectures to produce novel images from text prompts.
-
Audio Processing and Music Generation: Transformers are also used for audio tasks by treating sound waves as sequences. These models can perform audio classification, transcription, and even music generation, showcasing the model's ability to process and generate time-based data beyond text.
-
Mathematics and Logic Tasks: Transformers are also applied in arithmetic and logic tasks, where they can learn patterns to solve math problems or understand logical sequences. This use of Transformers in domains traditionally reserved for symbolic AI demonstrates their versatility as general-purpose sequence models.
The Emergence of Large Language Models (LLMs)
With further scaling and architectural refinements, LLMs such as GPT-3, BERT, and T5 emerged from the foundation of the Transformer model. These models are pre-trained on diverse, extensive datasets—often sourced from the internet—enabling them to perform tasks such as translation, summarization, and conversation at near-human levels. The introduction of larger datasets and more parameters has allowed LLMs to surpass the limits of traditional Transformers, excelling in complex language generation and understanding tasks.
LLM Applications Enabled by the Transformer Foundation:
- Conversational AI: LLMs built on Transformers power advanced chatbots and virtual assistants, enabling applications that require contextual understanding over multi-turn conversations.
- Knowledge Retrieval and Summarization: Models like BERT are fine-tuned for tasks like document summarization and question answering, transforming how users interact with large information repositories.
- Multimodal Capabilities: Newer LLMs integrate text with images, audio, or video, allowing for multimodal interactions. This capability is pivotal for applications in augmented reality, interactive gaming, and assistive technologies.
The evolution from Transformers to LLMs exemplifies how a foundational architecture can be expanded and adapted to meet the growing demands of diverse, real-world applications. As research progresses, LLMs continue to push the boundaries of what is achievable with AI, setting the stage for even more integrated and sophisticated applications across industries.
Differences from Generative AI
While Large Language Models (LLMs) are often considered a subset of generative AI, there are important distinctions between the two. Generative AI is a broad term referring to artificial intelligence systems that generate new content, including text, images, audio, and video. LLMs, on the other hand, focus specifically on understanding and generating human language.
-
Scope of Content Creation: Generative AI encompasses models that produce a wide range of content types beyond text, such as images, music, and 3D graphics. Examples include diffusion models for images, such as those used by DALL-E, and variational autoencoders for creating new data types. In contrast, LLMs like GPT-4 or BERT are primarily designed for text-based tasks, including language understanding, translation, and summarization.
-
Model Architecture: LLMs are typically built on transformer-based architectures that are optimized for sequential text processing and understanding linguistic nuances. Generative AI models may utilize various architectures, including generative adversarial networks (GANs) and diffusion models, tailored for visual and auditory data. These models focus on creating content that matches a specific style or context, while LLMs focus on generating coherent and contextually appropriate text based on prompt input.
-
Applications and Use Cases: LLMs are specifically tuned for language-related applications, such as question answering, summarization, and conversational agents. They excel in contexts that require deep language comprehension, like virtual assistants and chatbots. Generative AI, however, finds use in creative industries like media and design, where models can generate unique images, videos, and music. Generative AI applications also extend into fields like product design, gaming, and medical imaging.
-
Data Training and Fine-Tuning: While both LLMs and generative AI models are trained on large datasets, the nature of the data differs significantly. LLMs require extensive language-based datasets to capture syntactic and semantic nuances. In contrast, generative AI models, such as GANs or diffusion models, are trained on diverse datasets, including images, videos, and audio samples, which allow them to recreate and innovate across various content types.
In summary, while LLMs are a specialized form of generative AI focused on language, generative AI includes a broader range of models and applications that extend into multimedia content creation and pattern recognition across domains.
3. Key Components of Large Language Models (LLMs)
The Transformer Architecture
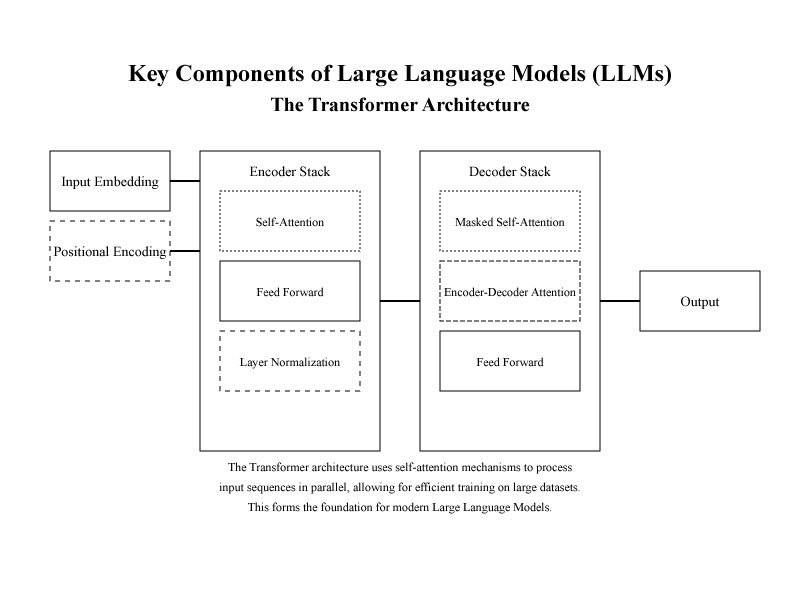
The Transformer architecture is the backbone of modern Large Language Models (LLMs). Introduced in 2017 by Vaswani et al. in their groundbreaking paper "Attention is All You Need," the Transformer revolutionized natural language processing by introducing a more efficient and scalable architecture compared to earlier models like Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs).
The main innovation of the Transformer lies in its use of self-attention mechanisms, which allow the model to evaluate the importance of each word in a sentence relative to the others, irrespective of their position in the text. This approach enables the model to process entire sequences of words simultaneously, making it highly efficient for handling long-range dependencies in language.
In comparison, RNNs and LSTMs (Long Short-Term Memory networks) process words sequentially, making them slower and prone to losing important context when dealing with longer sentences or paragraphs. Additionally, RNNs struggle with the problem of vanishing gradients, which makes it difficult to retain information over extended sequences. Transformers overcome these limitations by focusing on the relationships between all words at once, using multi-head attention to capture different aspects of word relationships within the text.
The Transformer architecture is the foundation of many state-of-the-art LLMs, including models like GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers). Its ability to scale effectively with larger datasets and more parameters has made it indispensable in advancing the capabilities of LLMs.
Additional Components in Transformer-Based Models:
- Embedding Layers: LLMs begin by transforming raw text into embeddings, which are vector representations of words or tokens. These embeddings capture syntactic and semantic relationships, allowing the model to understand context and nuances in language.
- Feedforward Layers: Feedforward neural layers apply non-linear transformations, enabling the model to derive high-level abstractions of text, enhancing its understanding of user intent and context.
- Attention Layers: Attention layers allow LLMs to focus on specific parts of a sentence, assigning varying weights to tokens based on their relevance to the task. This self-attention is critical for generating accurate, context-aware outputs.
Training Process
Training a Large Language Model is a resource-intensive process that involves feeding the model vast amounts of data and iteratively adjusting its parameters to improve performance. The training process can be divided into several stages:
-
Data Collection: The first step in training an LLM is gathering massive datasets that contain a diverse range of text. These datasets may include content from websites, books, research papers, and other text sources. The diversity of the data is crucial for enabling the model to handle various linguistic tasks and adapt to different contexts.
-
Tokenization: Before the data can be used, it must be preprocessed through a method called tokenization, where text is broken down into smaller units, such as words, subwords, or characters. This allows the model to process language at a granular level, helping it understand the relationships between individual tokens and their context within the text.
-
Training the Model: The training itself is performed using deep learning techniques, where the model is tasked with predicting the next word or token in a sequence based on the preceding context. During this phase, the model adjusts its internal parameters (known as weights) using backpropagation and gradient descent to minimize errors. This training is done over several epochs (complete passes over the dataset) to refine the model’s accuracy.
-
Scale of Data and Computational Intensity: One of the defining features of LLMs is the scale of data and computational resources required for training. Models like GPT-3 are trained on hundreds of billions of words, and training can take weeks or even months using thousands of high-powered GPUs. The vast size of these models (often measured in billions or trillions of parameters) means that training them requires not only massive datasets but also significant computational power and storage capabilities. Additionally, the ability to maintain large language models is essential, as scaling and maintaining these models can be particularly difficult and resource-intensive, indicating the operational complexities involved.
-
Evaluation and Tuning: After the initial training, the model is evaluated using validation datasets to assess its performance. Fine-tuning is often necessary to adjust the model’s weights for better performance on specific tasks or to mitigate issues like overfitting, where the model becomes too specialized to the training data and struggles with new, unseen text.
Training LLMs is computationally expensive, both in terms of time and energy, which raises concerns about the environmental impact of large-scale training efforts. However, advancements in optimization techniques and model efficiency are helping to mitigate some of these challenges.
The Importance of Pre-Training and Fine-Tuning
One of the key advantages of LLMs lies in their two-step training process: pre-training and fine-tuning.
-
Pre-Training: During the pre-training phase, the LLM is exposed to vast amounts of text data, learning the statistical relationships between words and phrases across many different contexts. This phase is general in nature, meaning the model is not tailored to any specific task but instead develops a broad understanding of language. Pre-training typically involves unsupervised learning, where the model learns to predict the next word in a sequence without human-labeled data.
-
Fine-Tuning: After pre-training, the model undergoes fine-tuning, where it is adapted to a specific task or domain. For example, an LLM might be fine-tuned to perform tasks such as answering questions, summarizing text, or generating code. Fine-tuning is often done with smaller, task-specific datasets and involves supervised learning, where the model is trained with labeled data to improve its performance in a particular area.
The benefits of this approach are numerous. Pre-training allows the model to acquire a vast amount of general knowledge, which can then be applied to a wide range of downstream tasks. Fine-tuning ensures that the model is better suited to specific use cases, improving its accuracy and performance in specialized applications.
However, there are also challenges associated with this process. Pre-training requires vast amounts of data and computational resources, making it costly and time-consuming. Fine-tuning, while more targeted, can introduce biases if the training data is not sufficiently diverse or representative of real-world use cases. Additionally, fine-tuning can sometimes lead to overfitting, where the model performs exceptionally well on the fine-tuning data but struggles with new, unseen data.
The combination of pre-training and fine-tuning allows LLMs to be both versatile and highly specialized, making them powerful tools in various applications across industries. As optimization techniques continue to improve, the efficiency and accessibility of LLMs are expected to increase, enabling even more widespread use in the future.
4. Data Preparation for LLM Development
Data preparation is a foundational step in building effective Large Language Models (LLMs). The quality, diversity, and structure of data directly impact the performance, reliability, and generalizability of LLMs. Preparing data for LLMs involves multiple phases, including data acquisition, cleaning, preprocessing, and structuring. These processes transform raw text or code data into a structured, high-quality format suitable for tasks like training, fine-tuning, and Retrieval-Augmented Generation (RAG).
Advanced Data Preparation Techniques
-
Data Acquisition and Curation: LLMs require vast, diverse datasets to generalize effectively across tasks and domains. High-quality data sources include web-crawled content, academic papers, books, and specialized datasets. However, the acquisition process must also consider copyright compliance, data ethics, and privacy concerns. Leveraging automated crawling and filtering tools with ethical scraping policies can ensure a robust and compliant data pipeline.
-
Deduplication and Noise Reduction: Raw text data often includes duplicates and irrelevant content, which can skew training and lead to model biases. Advanced deduplication algorithms, such as MinHash and Locality-Sensitive Hashing (LSH), are employed to efficiently identify and remove duplicates at scale, especially useful for massive datasets. Additionally, noise reduction techniques, including filtering based on quality scores or relevance, help maintain data integrity by excluding low-quality or irrelevant content.
-
Data Structuring and Tokenization: Proper structuring and tokenization are crucial for model interpretability and efficiency. Tokenization techniques vary, with Byte-Pair Encoding (BPE) and SentencePiece being popular choices for handling diverse language inputs. Optimizing tokenization granularity, especially for multilingual and code datasets, improves model comprehension and reduces computational overhead by minimizing token sparsity.
-
Language Identification and Content Classification: For LLMs trained on multilingual datasets, language identification and classification ensure that each input is processed in the appropriate linguistic context. Automated language detectors, based on machine learning models, help filter, sort, and categorize data, enhancing the model’s ability to handle multilingual or domain-specific text accurately. Content classification further allows filtering by topic, relevance, or industry for models requiring specialized knowledge.
-
Data Anonymization and Privacy Management: Ensuring data privacy, especially in domains like healthcare or finance, is essential for responsible AI development. Techniques such as differential privacy, k-anonymity, and data masking allow sensitive information to be anonymized while retaining data utility. Privacy-preserving transformations are increasingly integrated into data pipelines to comply with regulations like GDPR and CCPA, balancing data richness with ethical considerations.
The Role of Data-Prep-Kit (DPK)
The Data-Prep-Kit (DPK) is a scalable, open-source toolkit designed to streamline data preparation workflows for LLM applications. Developed with modularity and scalability in mind, DPK supports various runtimes such as Ray and Spark, and can scale from local environments to distributed Kubernetes clusters, accommodating the high data volumes required for LLMs.
Key Features of DPK
-
Scalability and Flexibility: DPK allows for flexible deployment, enabling data preparation on a laptop for initial experimentation or on a large cluster for production-scale tasks. By leveraging distributed computing frameworks like Ray and Spark, DPK efficiently handles massive datasets, ensuring timely data processing.
-
Modular Transformation Pipelines: DPK includes pre-built modules for transformations such as deduplication, language identification, and document chunking, essential for optimizing data for LLMs. These modules can be dynamically chained, enabling customizable workflows for project-specific requirements.
-
Automation and No-Code Pipeline Execution: With integration support for Kubeflow Pipelines (KFP), DPK provides a no-code interface for building and executing data preparation workflows. This feature is particularly beneficial for non-technical users, allowing them to handle data transformations without extensive knowledge of distributed computing.
-
Customization and Extensibility: DPK’s modular framework allows users to build and integrate custom transformations tailored to unique model requirements. This adaptability is particularly valuable for teams working on domain-specific LLMs, as it enables precise control over data preparation steps.
Benefits of Robust Data Preparation
Implementing a structured and automated data preparation pipeline with tools like DPK enhances the efficiency and quality of the entire model development process. By automating redundant or complex steps, DPK minimizes human intervention, allowing data scientists to focus on model improvement rather than manual data processing. Additionally, advanced data preparation practices ensure that LLMs are built on a foundation of clean, diverse, and representative data, leading to more reliable, generalizable, and accurate model outputs.
5. Applications of Large Language Models (LLMs)
Enhancing Customer Experience
Large Language Models (LLMs) have revolutionized customer experience by enabling advanced chatbots, virtual assistants, and automated customer service solutions. Leveraging their deep understanding of language and context, LLMs allow businesses to provide highly personalized, human-like interactions, vastly improving customer engagement and satisfaction.
-
Chatbots: LLM-powered chatbots manage a wide range of customer inquiries, from answering FAQs to providing real-time troubleshooting and escalating issues to human agents when necessary. This reduces response times and enhances service efficiency. For example, companies that have integrated LLMs into their customer service platforms report faster query resolution and higher customer satisfaction, as LLMs can handle both simple and complex queries effectively.
-
Virtual Assistants: Platforms such as Apple’s Siri, Amazon Alexa, and Google Assistant leverage LLMs to understand and respond to complex user requests in natural language. These assistants continuously learn user preferences, offering increasingly personalized recommendations and assisting with daily tasks. LLMs enable these virtual assistants to respond contextually, making interactions smoother and more intuitive.
-
Customer Service Automation: In sectors like retail and hospitality, LLMs automate routine customer interactions, such as answering repetitive queries and guiding customers through self-service options. By automating these tasks, companies can reduce operational costs while maintaining high-quality service. Businesses report significant efficiency gains, as LLMs streamline customer communication, minimize wait times, and free human agents to focus on more intricate issues.
Content Generation and Creativity
LLMs are transforming content generation processes across industries like publishing, marketing, and social media. Their ability to produce text that resembles human writing enables organizations to generate content at scale, customize messaging, and explore creative possibilities.
-
Publishing and Marketing: LLMs assist publishers in drafting articles, generating summaries, and creating marketing content tailored to target audiences. For instance, LLMs can produce content variations based on user data, enhancing engagement and conversion rates. With platforms such as NVIDIA's generative AI tools, companies can automate social media posts, blog articles, and targeted advertising, reducing production costs and enabling teams to focus on creative strategy.
-
Creative Writing: In entertainment and media, LLMs support content creators by brainstorming ideas, crafting narrative structures, and even generating first drafts of stories or scripts. This has proven invaluable for novelists, screenwriters, and game developers who use LLMs to enhance the creative process. While LLMs cannot entirely replace human creativity, they provide a powerful tool for overcoming writer’s block and expanding creative exploration.
-
Advertising and Social Media Content: Marketing teams utilize LLMs to quickly produce a wide range of ad copy and social media content that aligns with brand voice and audience preferences. Platforms like Jasper AI allow marketers to generate and test different versions of ad copy, maximizing audience engagement and refining brand messaging based on analytics.
Language Translation and Localization
LLMs are essential tools in bridging language barriers and enhancing global communication. Unlike traditional translation tools, LLMs provide contextual and nuanced translations, which are invaluable for businesses targeting international markets.
-
Machine Translation: LLMs, such as those utilized by Microsoft’s Azure Translator, offer high-accuracy translations across multiple languages. These models understand linguistic subtleties, enabling them to convey accurate meaning while capturing regional idioms and cultural references. This capability is especially important in sectors like tourism, e-commerce, and online education, where communicating effectively in local languages is key to reaching a global audience.
-
Localization: Beyond translation, LLMs assist in adapting marketing materials, websites, and product documentation to align with cultural norms and preferences of target regions. For example, LLMs can adjust tone, style, and idiomatic expressions in marketing content to better resonate with audiences in specific markets, helping businesses expand their reach and foster brand loyalty internationally.
-
Multilingual Support for Customer Service: LLMs provide real-time multilingual support in customer service applications, enabling companies to offer seamless customer interactions across various languages. This is particularly valuable for companies with a global customer base, as LLMs can instantly translate and respond to inquiries, eliminating the need for separate teams for each language.
Knowledge Management and Internal Assistance
LLMs streamline knowledge management within organizations, making it easier to access and analyze large volumes of data. By organizing and retrieving information efficiently, they enhance decision-making processes and support employee productivity.
-
Internal Knowledge Bases: Companies like PwC have implemented LLMs to power internal tools such as ChatPwC, which provides employees with instant answers to queries and access to relevant documents. LLMs categorize, summarize, and retrieve information from vast data repositories, making knowledge easily accessible and significantly reducing time spent searching for information.
-
Data Analysis and Summarization: LLMs can analyze and summarize complex reports, such as financial documents, research studies, or technical manuals, making critical insights readily available to decision-makers. For example, LLMs can synthesize key points from lengthy financial statements, allowing executives to make informed decisions more efficiently.
-
Training and Onboarding: LLMs are used to create intelligent training modules that guide new employees through onboarding processes by providing context-specific information. For example, Ricoh’s LLM-based onboarding solution significantly reduced training time for technicians by providing real-time assistance and troubleshooting support, thereby improving operational efficiency.
Healthcare Applications
In healthcare, LLMs support diagnosis, treatment planning, and patient engagement by analyzing vast medical datasets and enhancing physician decision-making.
-
Clinical Decision Support: LLMs trained on medical literature assist healthcare providers in diagnosing diseases, suggesting treatment options, and identifying potential drug interactions. For example, LLMs integrated with electronic health records (EHRs) help doctors access relevant medical information rapidly, reducing diagnostic errors and improving patient outcomes.
-
Patient Interaction: Medical chatbots powered by LLMs can engage with patients, providing answers to common health questions, scheduling appointments, and even triaging symptoms. These chatbots allow healthcare providers to manage large patient volumes more effectively while maintaining a high standard of care.
-
Medical Research: In pharmaceutical and life sciences, LLMs are used to curate and summarize scientific literature, accelerating the research process. This is particularly valuable in drug discovery and genetic research, where LLMs analyze complex datasets to identify promising therapeutic candidates or understand genetic relationships.
Software Development and Code Generation
LLMs play an instrumental role in software development, offering code suggestions, generating snippets, and even creating entire functions based on natural language prompts.
-
Code Generation and Assistance: Tools like GitHub Copilot, built in partnership with OpenAI, provide real-time coding suggestions, making programming more accessible and reducing time spent on routine coding tasks. LLMs assist developers by generating functions, suggesting improvements, and helping with debugging.
-
Documentation and Comment Generation: LLMs streamline code documentation by generating comments and documentation based on code analysis. This improves code readability and maintenance, especially in large codebases where understanding the intent behind complex functions can be challenging.
-
Automated Testing: LLMs support quality assurance by generating test cases based on code functionality and user requirements. They analyze code to identify potential issues and suggest testing scenarios, improving software reliability and accelerating the testing phase.
6. Benefits of Large Language Models
Improved Natural Language Understanding
Large Language Models (LLMs) have revolutionized the field of natural language processing (NLP) by enabling machines to process and understand human language with unprecedented accuracy. One of the key benefits of LLMs is their ability to achieve improved natural language understanding. By leveraging transformer architectures, such as those found in GPT-3, GPT-4, and other models, LLMs can capture the nuances of human language, including context, sentiment, and even subtle meanings in conversation. The result is more accurate comprehension and generation of text, making LLMs invaluable in applications like chatbots, virtual assistants, and translation services.
For instance, companies like OpenAI have demonstrated that models like ChatGPT can accurately interpret and respond to a wide range of queries, from simple factual questions to more complex inquiries involving multiple layers of context. This improved understanding enables LLMs to provide more relevant and context-aware responses, enhancing user experience across various platforms. Moreover, their ability to process vast amounts of data allows them to continually refine their language models, further boosting performance.
Scalability and Flexibility
The scalability of LLMs is another significant advantage, making them adaptable across different industries and tasks. One of the strengths of LLMs lies in their ability to scale with the size of data and computational resources. This scalability allows them to be fine-tuned for specific domains, whether it be healthcare, legal, financial services, or even materials science. The transformer-based architecture of LLMs supports this adaptability, as seen in models like BERT and LLaMA, which have been successfully adapted to a wide range of industry-specific tasks.
Furthermore, LLMs are flexible enough to accommodate multiple languages and contexts, facilitating their use in global applications. For example, LLMs are increasingly being used in real-time translation services, enabling seamless communication across different languages and cultural contexts. Their ability to handle multilingual datasets and adapt to various languages ensures that they can provide accurate translations while maintaining the nuances of the source material.
Productivity and Efficiency Gains
One of the most transformative aspects of LLMs is their ability to enhance productivity and efficiency across industries. By automating repetitive tasks such as content moderation, document summarization, and even customer service inquiries, LLMs free up human workers to focus on more strategic and creative tasks. In content generation, for example, LLMs can quickly produce human-like text, significantly reducing the time required for tasks like report writing, article generation, or creative writing.
In industries like healthcare and legal services, LLMs have been applied to automate the analysis of large documents, extracting relevant information and summarizing key points. This reduces the time professionals spend on manual review and improves overall workflow efficiency. Additionally, by integrating LLMs with other AI tools, organizations can streamline complex processes, leading to greater operational efficiency.
7. Challenges and Limitations
Ethical Considerations
Large Language Models (LLMs) present a variety of ethical dilemmas, particularly around fairness, bias, and the attribution of responsibility. A key concern is that LLMs can perpetuate biases embedded in their training data, leading to unfair outcomes. For example, bias in LLMs can manifest in subtle ways, affecting marginalized groups or reflecting societal stereotypes. This issue poses challenges in areas like recruitment, healthcare, and law, where algorithmic decisions might reinforce discriminatory patterns.
Moreover, LLMs raise questions about the responsibility for outputs. When an LLM generates harmful content—such as misinformation or misleading information—questions arise about who should be held accountable: the developer, the user, or the model itself. According to a study by Oxford University, users of these technologies may not be fully responsible for positive outcomes generated by LLMs, yet they are held accountable for harmful consequences, such as propagating misinformation. This “credit-blame asymmetry” complicates the ethical landscape, necessitating clearer guidelines for using LLMs in contexts like publishing, education, and content creation.
Data Privacy and Security Risks
LLMs face significant challenges when it comes to data privacy and security. These models are trained on vast amounts of data, which can include sensitive personal information. As such, they are vulnerable to data breaches, privacy leaks, and misuse of confidential information. For instance, during training, LLMs might inadvertently memorize sensitive data points, making them susceptible to extraction attacks, where adversaries could query the model to recover personal information or proprietary data.
Additionally, LLMs can be manipulated for malicious purposes. Attackers could leverage LLMs to carry out phishing attacks, social engineering schemes, or even more sophisticated forms of cybercrime. The models can be exploited to generate highly convincing but harmful content, contributing to a rise in network-level attacks like phishing, where users are tricked into revealing sensitive information.
High Resource Demands
The computational power required to train and deploy LLMs is immense. Large models, like GPT-3 or GPT-4, involve billions or even trillions of parameters, necessitating significant resources for both training and inference. This includes vast amounts of energy consumption, which has led to concerns about the environmental impact of LLMs. The carbon footprint of training these models can be substantial, exacerbating concerns about sustainability in AI development.
In addition to energy consumption, the financial cost of running LLMs is also prohibitive for many organizations. This raises concerns about accessibility, as only large tech companies or well-funded institutions may have the resources to develop and maintain these models. As a result, there is an increasing divide between organizations that can afford to implement LLMs and those that cannot, potentially widening the gap in AI adoption across industries.
Accuracy and Reliability
Despite their impressive capabilities, LLMs often face challenges in delivering consistently accurate and reliable results. While these models are adept at generating human-like text, they can also produce incorrect, misleading, or biased outputs, which can be problematic in high-stakes environments like healthcare, finance, or law.
For instance, LLMs may generate responses that seem plausible but are factually incorrect. This can lead to misinformation, especially when the models are used in automated systems that require high levels of accuracy. Furthermore, LLMs can struggle with nuanced tasks that require deep contextual understanding, leading to reliability issues in specialized applications. These limitations highlight the need for continued refinement in LLM design and deployment to ensure their outputs are not only fluent but also trustworthy.
The challenges and limitations of LLMs span ethical considerations, privacy risks, high resource demands, and issues with accuracy. Addressing these challenges is essential to maximize the benefits of LLMs while minimizing their risks across various industries and applications.
8. Hallucinations in Large Language Models (LLMs)
One of the significant challenges with Large Language Models (LLMs) is their tendency to produce hallucinations. In this context, hallucination refers to instances when an LLM generates information that appears coherent and accurate but is actually incorrect, misleading, or entirely fabricated. This phenomenon poses serious challenges for applications where accuracy and reliability are paramount, such as healthcare, legal, and customer support services.
Why Hallucinations Occur in LLMs
-
Prediction-Based Nature: LLMs are designed to predict the next word or phrase based on the input they receive. Since they are not genuinely "aware" of facts, they may generate plausible-sounding content without a grounding in truth. Unlike a database that retrieves exact information, LLMs rely on probabilities derived from patterns in the training data, which can lead them to "guess" when they encounter ambiguous or incomplete queries.
-
Limitations of Training Data: LLMs are trained on vast datasets sourced from the internet and other repositories. If the training data contains errors, biases, or outdated information, the model may incorporate these inaccuracies into its responses. Additionally, because the training process does not involve real-time verification of facts, LLMs may present fictional information as factual.
-
Overgeneralization: LLMs generalize based on patterns they observe, which can sometimes lead to overconfidence in incorrect information. For instance, if a model frequently encounters associations between certain words or phrases, it may use them together in a way that sounds plausible but lacks factual basis. This issue is particularly evident in technical or specialized fields where nuances are critical.
Risks and Implications of Hallucinations
Hallucinations can have serious implications, especially when LLMs are used in fields requiring high levels of accuracy. For example:
- Healthcare: Incorrect medical information could lead to poor health outcomes or even harm to patients.
- Legal: Hallucinations in legal contexts might result in flawed advice, which could have severe consequences for clients.
- Finance: Inaccurate financial recommendations may mislead investors or clients, impacting financial decisions.
Mitigating Hallucinations in LLM Use
-
Human Review and Verification: One of the most effective strategies is incorporating human oversight in applications where LLM responses require validation. For instance, customer support agents can use LLMs to generate draft responses that they review before sending.
-
Model Fine-Tuning and Training on High-Quality Data: Fine-tuning LLMs with high-quality, domain-specific datasets can reduce the likelihood of hallucinations. By ensuring that the training data is current, factual, and relevant to the application, organizations can minimize erroneous outputs.
-
Real-Time Fact-Checking Systems: For applications with high factual accuracy demands, integrating real-time fact-checking mechanisms can enhance reliability. This approach involves cross-referencing generated responses with trusted databases, especially in fields like healthcare and finance.
-
User Awareness and Transparency: Ensuring that end-users understand the limitations of LLMs can help manage expectations and reduce reliance on generated outputs without verification. In high-stakes applications, clear disclaimers may also be necessary to alert users to the possibility of inaccuracies.
Future Directions for Reducing Hallucinations
Research into model architectures and training methodologies aims to address the hallucination issue. Potential advancements include:
- Reinforcement Learning with Human Feedback (RLHF): This method improves LLM performance by integrating human feedback, refining model responses to align more closely with factual information.
- Hybrid Systems Combining LLMs with Symbolic AI: Integrating LLMs with knowledge-based systems, such as symbolic AI or rule-based models, may help improve factual accuracy by grounding LLM outputs in verified information sources.
By understanding and addressing hallucinations, developers and organizations can work towards safer and more reliable applications of LLMs, particularly in sensitive or high-stakes fields.
9. Evaluation of Large Language Models (LLMs)
The evaluation of Large Language Models (LLMs) is a nuanced process that requires a multifaceted approach to accurately assess model performance, reliability, and alignment with application-specific requirements. Given their complex architectures and diverse use cases, LLMs present unique challenges for evaluation, especially when it comes to tasks requiring contextual accuracy, factual integrity, and nuanced language understanding.
Key Evaluation Metrics and Techniques
-
Traditional Automated Metrics:
Standard metrics such as BLEU, ROUGE, and METEOR are commonly used for tasks like translation and summarization, where they measure n-gram overlap between model output and reference texts. However, while BLEU and ROUGE provide a baseline for textual similarity, they are often biased towards shorter, simpler responses, and may fail to capture the semantic accuracy and contextual relevance of longer or complex outputs. BERTScore, which uses contextual embeddings, offers a more advanced approach by evaluating the semantic similarity of generated text, potentially addressing some limitations of surface-level n-gram metrics. -
Advanced Evaluation Frameworks:
Recent frameworks such as IBM’s FM-eval and Google’s Vertex Gen AI Evaluation Service are tailored for rigorous LLM assessment across multiple dimensions. These frameworks incorporate both computation-based metrics and human-based evaluations, enabling a comprehensive analysis of model outputs. For example, Vertex Gen AI’s AutoSxS feature leverages LLMs as evaluators, enabling comparative analysis of different models with explanations and confidence scores for each judgment. This hybrid evaluation approach integrates human-like assessments with automated precision, enhancing reliability for high-stakes applications. -
Human-in-the-Loop Evaluation:
Human evaluations remain the gold standard for assessing aspects like coherence, fluency, and contextual appropriateness that are difficult to quantify through automated metrics. In high-stakes applications, such as legal or medical information generation, human oversight is particularly crucial to validate model outputs. Human evaluators assess LLMs on parameters such as factual consistency, ethical alignment, and user satisfaction, complementing automated metrics and providing a comprehensive view of the model’s performance. -
Task-Specific Benchmarking:
Specialized benchmarks such as TruthfulQA and MMLU (Massive Multitask Language Understanding) provide standardized test sets that evaluate LLMs on specific abilities, such as question answering accuracy and multi-domain knowledge. These benchmarks simulate real-world conditions, allowing developers to evaluate models’ proficiency across various domains and identify knowledge gaps or reasoning inconsistencies. For instance, TruthfulQA assesses the model's ability to provide factual answers, addressing the issue of hallucination by comparing responses to verified truths.
Model Evaluation vs. System Evaluation
Evaluating LLMs often extends beyond the model’s standalone performance. Model evaluation focuses on intrinsic metrics like accuracy, coherence, and linguistic diversity, assessing the LLM’s raw capability in language understanding and generation. In contrast, system evaluation involves the assessment of LLM-integrated applications in a production environment, addressing factors such as scalability, latency, and interaction with external systems like APIs or databases. System evaluation provides a holistic view of LLM deployment, ensuring that the model performs reliably within an integrated workflow and meets user expectations in real-time applications.
Challenges in LLM Evaluation
Evaluating LLMs presents several technical and methodological challenges:
-
Bias and Ethical Concerns:
LLMs inherit biases from their training data, and evaluation frameworks must include bias detection mechanisms to identify and mitigate unintended outputs. Metrics specifically designed for toxicity and bias, such as the ToxiGen dataset, help researchers ensure that models produce safe and ethical outputs, particularly for applications in sensitive areas like healthcare and finance. -
Semantic vs. Syntactic Evaluation:
Metrics like BLEU and ROUGE are limited in their ability to evaluate semantic correctness, as they rely primarily on lexical overlap. Embedding-based metrics, such as BERTScore, offer an improvement by evaluating the semantic similarity of responses, yet may still lack sensitivity to context-specific nuances. Hybrid methods that combine both syntactic and semantic metrics, or incorporate LLMs as evaluators, can yield more reliable insights into model performance. -
Adaptability to Diverse Use Cases:
As LLMs are applied in various domains, a single evaluation metric is rarely sufficient. Customized evaluation criteria and task-specific benchmarks are essential to ensure that LLMs meet the requirements of specialized applications. For example, in customer service, metrics might prioritize response latency and user satisfaction, while in educational applications, correctness and pedagogical alignment take precedence. -
Continuous Monitoring and Iterative Improvement:
The dynamic nature of LLM applications necessitates ongoing evaluation to monitor performance over time. Metrics such as latency and user feedback, combined with periodic fine-tuning, help maintain model relevance and adaptability to evolving requirements. Continuous integration of evaluation results into the development lifecycle is essential for maintaining high-performance standards and reducing risks in production.
In summary, evaluating LLMs is a multi-layered process that requires a combination of automated metrics, human evaluations, and task-specific benchmarks to accurately capture model performance and address challenges related to bias, accuracy, and adaptability. As LLM applications expand across industries, robust evaluation frameworks will play a critical role in ensuring that these models are reliable, ethical, and aligned with end-user needs.
10. Future of Large Language Models
Advancements in Model Efficiency
The evolution of Large Language Models (LLMs) increasingly emphasizes efficiency improvements to address computational and environmental challenges. Innovations in transformer architecture are crucial here, particularly in refining attention mechanisms to reduce the traditionally high quadratic complexity associated with processing long sequences of text. Recent approaches, such as sparse attention and low-rank factorization, help maintain model performance while lowering computational costs. These improvements in architecture allow for more energy-efficient training and inference, making it feasible to deploy LLMs in real-world applications with reduced environmental impact and cost.
Democratization of LLMs
Democratizing access to LLMs involves creating smaller, more efficient models that can be used by a broader audience beyond large tech corporations. Techniques like parameter-efficient tuning and distillation are enabling models to perform competitively at reduced scales, allowing smaller businesses, independent developers, and researchers to use LLMs without extensive computational resources. Cloud platforms and open-source initiatives, such as AWS’s Amazon Bedrock and Elastic’s Elasticsearch Relevance Engine, are playing a pivotal role in this shift. These platforms provide pre-trained LLMs, allowing users to integrate advanced language processing capabilities into applications with less specialized infrastructure.
Hyper-Personalization in AI Applications
LLMs are advancing toward hyper-personalization by incorporating context-awareness and fine-tuning to cater specifically to user needs. This level of personalization has significant implications across industries. In healthcare, for example, it could lead to customized patient interactions and treatment recommendations. In marketing, LLMs could offer tailored content, ads, or product suggestions. By leveraging large, diverse datasets and refining output for specific use cases, LLMs promise to enhance the user experience through content that feels uniquely relevant to each individual.
Integration with Other AI Technologies
The integration of LLMs with complementary AI technologies, such as computer vision and reinforcement learning, is paving the way for more comprehensive AI solutions. For example, multimodal models that combine language processing with image analysis can support complex tasks in fields like autonomous driving, where understanding both text-based commands and visual inputs is critical. Furthermore, integrating LLMs with reinforcement learning could improve adaptive decision-making in dynamic environments, such as robotics and gaming. This convergence of technologies is expected to extend the capabilities of AI systems, enabling them to perform more diverse tasks with greater context-awareness and autonomy.
Ethical Considerations and Responsible AI Development
As LLMs become more integrated into critical applications, ethical considerations, such as reducing biases, ensuring data privacy, and addressing potential misinformation, are increasingly important. Developers are implementing regular evaluation cycles, monitoring for bias, and employing frameworks for transparency and accountability. Techniques like differential privacy and federated learning are emerging to enhance user privacy by minimizing data exposure during training. These measures are crucial for aligning LLM development with principles of responsible AI, ensuring these models contribute positively to society without unintended harm.
11. AI Agents and LLMs
Large Language Models (LLMs) are integral to the development and enhancement of AI agents, which are autonomous systems designed to interact with users, perform complex tasks, and make decisions. AI agents leverage the natural language understanding and generation capabilities of LLMs to operate in real-world applications, adapting to user needs and contexts in increasingly sophisticated ways.
How LLMs Power AI Agents
-
Contextual Understanding and Dynamic Interaction: AI agents rely on LLMs to understand complex language inputs and respond dynamically. LLMs provide these agents with the ability to process multi-turn conversations, remember prior interactions, and maintain context, which is crucial for applications in customer service, personal assistants, and autonomous support bots.
-
Decision-Making and Problem-Solving: Equipped with the advanced processing power of LLMs, AI agents can perform complex reasoning, retrieve information from vast knowledge bases, and make informed decisions. This capability is particularly beneficial in fields like finance, where AI agents assist with portfolio management, or in healthcare, where they can support diagnostic decision-making.
-
Task Automation and Workflow Optimization: AI agents automate repetitive or time-consuming tasks by using LLMs to process information, extract insights, and generate actionable outputs. For instance, in business operations, LLM-driven AI agents can handle document processing, draft emails, analyze reports, and even automate scheduling, freeing human workers to focus on higher-level tasks.
-
Personalized Experiences: By leveraging user data and learning from interactions, AI agents with LLMs can deliver highly personalized experiences. Examples include recommendation engines that suggest tailored content, virtual shopping assistants that remember preferences, and fitness or wellness bots that provide individualized guidance. LLMs allow these agents to continuously learn and adapt to each user, enhancing satisfaction and engagement.
Examples of LLM-Driven AI Agents
-
Customer Support Bots: Companies deploy AI agents powered by LLMs to handle customer inquiries, troubleshoot issues, and provide step-by-step guidance. With the contextual awareness of LLMs, these bots can resolve a wide range of customer issues autonomously, escalating to human agents only when necessary, thereby reducing wait times and improving user experience.
-
Virtual Health Assistants: In healthcare, LLM-driven agents assist patients by answering medical queries, guiding them through symptom checks, and even managing appointment bookings. For example, a virtual health assistant can interact with patients regarding their symptoms, suggest next steps, and help them schedule a consultation if needed, all while adhering to privacy regulations.
-
Productivity Tools: AI agents like Notion AI and Microsoft Copilot use LLMs to assist with tasks like drafting documents, summarizing content, or generating ideas. These agents leverage LLMs’ language generation capabilities to help users work more efficiently, providing actionable insights and automating routine tasks.
-
Education and Training: In educational settings, AI agents powered by LLMs act as tutors, answering questions, generating practice problems, and offering feedback on student responses. By adapting to the learning pace and style of individual students, these agents support personalized education and enhance learning outcomes.
Challenges and Considerations
While LLMs enable powerful capabilities for AI agents, challenges remain in ensuring accuracy, managing data privacy, and avoiding biases. Continuous monitoring and ethical considerations are essential to prevent unintended outputs and to ensure that AI agents provide reliable and equitable service to all users. Additionally, balancing human oversight with autonomy is critical, particularly in sensitive applications like healthcare and finance, where decisions can have significant impacts.
12. Examples of Popular Large Language Models
Large Language Models (LLMs) have revolutionized artificial intelligence, significantly advancing natural language processing (NLP) and understanding. Each model offers unique strengths and capabilities, contributing to breakthroughs in various AI applications. This overview examines some of the most prominent LLMs impacting the industry in 2024:
BERT (Bidirectional Encoder Representations from Transformers) - 2018
- Developed by: Google
- Key Innovation: Introduced a bidirectional approach to language modeling, allowing it to understand the context of words based on both preceding and following text. This significantly improved performance on tasks requiring nuanced language understanding.
- Impact: BERT set new benchmarks in several NLP tasks, including question answering and sentiment analysis. While no longer state-of-the-art, it remains influential and serves as a foundation for many subsequent models. Google uses BERT-derived models and other architectures in its search algorithms.
- Use Cases: Primarily used now as a foundational model for fine-tuning on specific downstream tasks.
GPT (Generative Pre-trained Transformer) series
- Developed by: OpenAI
- Key Innovation: Pioneered autoregressive language modeling, generating text by predicting the next word based on preceding context. This allows for impressive text generation capabilities, ranging from human-like conversation to creative writing and code generation. The series has evolved significantly, from GPT-3 to the more powerful and versatile GPT-3.5-turbo and GPT-4.
- Impact: The GPT series, especially GPT-4, has significantly advanced conversational AI and creative content generation. ChatGPT, a popular conversational AI interface, utilizes GPT models.
- Use Cases: Powers conversational AI applications like ChatGPT, content creation tools, code generation assistants, and more. GPT-4's capabilities extend to tasks like image understanding and reasoning.
RoBERTa (Robustly Optimized BERT Pretraining Approach) - 2019
- Developed by: Meta (formerly Facebook AI)
- Key Innovation: Optimized BERT's training process by using more data and training for longer, resulting in improved performance and robustness.
- Impact: Achieved state-of-the-art results on various NLP benchmarks, surpassing BERT in several areas.
- Use Cases: Widely used in sentiment analysis, customer service automation, and research applications.
Claude - 2023
- Developed by: Anthropic
- Key Innovation: Focuses on producing safer, more helpful, and more aligned AI outputs, mitigating harmful or biased responses.
- Impact: Offers a strong alternative for applications requiring responsible and ethical AI usage.
- Use Cases: Suitable for customer service, healthcare, legal, and other sectors prioritizing user trust and safety.
Gemini - 2023
- Developed by: Google DeepMind
- Key Innovation: Designed as a native multimodal model, processing and integrating text, images, audio, video, and code.
- Impact: Expands LLM capabilities beyond text, enabling more complex and interactive applications.
- Use Cases: Emerging applications in scientific analysis, real-time multimedia translation, content creation, and potentially robotics.
XLNet (Extreme Language Modeling) - 2019
- Developed by: Google
- Key Innovation: Combines autoregressive and autoencoding approaches to improve bidirectional context understanding and long-range dependency modeling.
- Impact: Offered performance improvements over BERT on some tasks, particularly those involving long sequences.
- Use Cases: Used in research and applications requiring deep contextual understanding, like analyzing legal documents.
T5 (Text-to-Text Transfer Transformer) - 2019
- Developed by: Google
- Key Innovation: Frames all NLP tasks as text-to-text problems, simplifying and unifying the model's application across various tasks.
- Impact: Provides a versatile framework for various NLP tasks, from summarization and translation to question answering.
- Use Cases: Used in automated content generation, text summarization, and translation services.
The rapid evolution of LLMs continues to shape the landscape of artificial intelligence. These models empower innovative solutions across various industries, from customer service and research to creative content generation and beyond. While this overview highlights prominent models, the field is dynamic, with new architectures and advancements emerging constantly, promising even more transformative applications in the future.
13. Practical Takeaways for Businesses
Large language models (LLMs) offer transformative opportunities for businesses of various sizes, enabling them to gain a competitive advantage in several key areas. Here's how businesses can practically leverage LLMs:
Leveraging LLMs for Competitive Advantage
-
: LLMs excel in automating repetitive tasks such as summarization, content moderation, and data entry. This allows businesses to reallocate human resources to more strategic tasks. For example, AI-driven customer relationship management tools boost efficiency by automating customer interactions, enabling sales teams to focus on higher-value tasks.
-
Enhancing Decision-Making: LLMs are powerful tools for processing large amounts of unstructured data, helping businesses gain insights that would be difficult to uncover manually. Organizations have used LLMs to analyze customer feedback and product reviews, improving decision-making around product development and marketing strategies.
-
Customer Service Automation: Businesses can use LLMs to enhance customer service by automating responses to frequently asked questions. This improves response times and customer satisfaction without increasing team size, reducing operational costs while maintaining a high level of service.
-
Content Generation: LLMs can generate content that mirrors human writing, aiding in content marketing efforts. Companies have used LLMs to create blog posts, social media content, and marketing materials, increasing output and engagement with their audience.
Key Considerations for Adopting LLMs
-
Cost and Infrastructure: Implementing LLMs can be expensive, particularly when considering the computing power required for training and inference. Smaller businesses may opt for pre-trained public LLMs to minimize costs, while larger organizations might benefit from customized models tailored to specific needs.
-
Data and Model Selection: Choosing the right model is crucial, as it must align with the company's specific tasks and objectives. Businesses should carefully evaluate the ROI of various LLMs based on their needs, whether for content generation, customer service, or data analysis.
-
Scalability and Adaptability: LLMs offer scalability across different industries and languages, allowing businesses to expand their global reach. LLMs can assist in tasks like translation, localization, and content generation in multiple languages, helping companies maintain consistent messaging worldwide.
-
Ethical Considerations: When implementing LLMs, businesses must address potential ethical issues, such as bias in training data, privacy concerns, and ensuring fairness in automated decision-making processes. Ethical AI deployment is essential for maintaining public trust and avoiding legal risks.
Large language models present a wealth of opportunities for businesses seeking to enhance productivity, customer service, and decision-making. However, successful adoption requires careful planning, including assessing the cost-benefit ratio, selecting the appropriate model, and ensuring ethical use. By strategically incorporating LLMs, companies can unlock new levels of efficiency and innovation while remaining competitive in a fast-evolving market.
14. Getting Started with Large Language Models
Steps to Implement LLMs in Your Organization
Implementing large language models (LLMs) in your organization can be a transformative but complex endeavor. Here are some practical steps to help you get started:
-
Determine Your Use Case: Identify the specific NLP task you want to address with LLMs, such as language translation, text summarization, or sentiment analysis. Clearly defining your use case will guide your model selection and implementation strategy.
-
Choose a Pre-Trained Model: Select a pre-trained LLM that aligns with your use case. Popular models like BERT, RoBERTa, and XLNet offer robust performance across various tasks. Evaluate the strengths and limitations of each model to find the best fit for your needs.
-
Fine-Tune the Model: Adapt the pre-trained model to your specific dataset through fine-tuning. Techniques like transfer learning or few-shot learning can help tailor the model to your use case, improving its performance on your specific tasks.
-
Prepare Your Data: Preprocess your dataset by cleaning the text, tokenizing it, and converting it into a format compatible with the LLM. Proper data preparation is crucial for effective model training and performance.
-
Train the Model: Train the fine-tuned model on your dataset using an appropriate optimizer and loss function. This step involves iteratively adjusting the model’s parameters to minimize errors and improve accuracy.
-
Evaluate the Model: Assess the performance of the trained model on a test dataset to ensure it meets your requirements. Use metrics like accuracy, precision, recall, and F1 score to evaluate its effectiveness.
-
Deploy the Model: Integrate the trained model into your application or system. Ensure that it works seamlessly with other components and is accessible to end-users.
-
Monitor and Maintain the Model: Continuously monitor the model’s performance and make necessary adjustments to maintain its effectiveness. Regular updates and retraining may be required to keep the model aligned with evolving data and use cases.
By following these steps, you can successfully implement LLMs in your organization, leveraging their power to solve complex NLP tasks and drive innovation.
15. Thoughts on the Future of LLMs
Large language models (LLMs) have emerged as transformative technologies with the potential to revolutionize industries ranging from healthcare and customer service to content creation and scientific research. By leveraging their capabilities, businesses of all sizes can unlock unprecedented efficiencies, improve decision-making, and offer more personalized customer experiences. These models enable organizations to automate complex tasks, scale their operations globally, and remain competitive in an increasingly digital economy.
However, while the potential benefits of LLMs are vast, it is equally important to address the ethical and technical challenges that come with their deployment. Issues such as data privacy, bias, and the significant environmental impact of training these models must be managed carefully to ensure responsible and sustainable use. Ethical AI practices, transparent governance, and continual monitoring will be essential as companies integrate LLMs into their workflows.
Looking ahead, the future of LLMs holds even more promise. Advances in model efficiency will reduce resource consumption, making these technologies more accessible and environmentally friendly. Efforts to democratize LLM technology will empower smaller companies and individual developers, fostering innovation across a wider range of sectors. Furthermore, hyper-personalization and the integration of LLMs with other AI technologies will enable more sophisticated and adaptive systems that can better meet the needs of users.
Large language models represent a powerful tool for driving innovation and growth across industries. As businesses consider adopting these models, they must balance the opportunities with careful attention to ethical considerations, ensuring that LLMs are used in ways that benefit society while minimizing potential risks. Staying informed about future advancements will be key to fully harnessing the potential of LLMs as they continue to evolve and shape the future of artificial intelligence.
References:
- EY | Four Steps for Implementing a Large Language Model (LLM)
- Forbes | Successful Real-World Use Cases For LLMs (And Lessons They Teach)
- Intel | Democratized Language Models Boost AI Development
- ScienceDirect | Future Trends in AI and NLP Models
- Oxford University | Tackling the Ethical Dilemmas of Large Language Models
- Cohere | Unlocking Productivity with Generative AI
- Zendesk | Large Language Models in Customer Experience
- NVIDIA | Content Creation with Generative AI
- Microsoft | AI and LLMs for Translation and Localization
- MIT News | LLMs Develop Their Own Understanding of Reality
- arXiv | Evaluating the Impact of Advanced LLM Techniques on AI-Lecture Tutors for a Robotics Course
- Google Cloud | Evaluating Large Language Models in Business
- IBM | LLM Evaluation
Please Note: Content may be periodically updated. For the most current and accurate information, consult official sources or industry experts.
Related keywords
- What is Artificial Intelligence (AI)?
- Explore Artificial Intelligence (AI): Learn about machine intelligence, its types, history, and impact on technology and society in this comprehensive introduction to AI.
- What is Generative AI?
- Discover Generative AI: The revolutionary technology creating original content from text to images. Learn its applications and impact on the future of creativity.
- What is Prompt Engineering?
- Prompt Engineering is the key to unlocking AI's potential. Learn how to craft effective prompts for large language models (LLMs) and generate high-quality content, code, and more.