Generative AI has transformed industries, allowing the creation of content, solutions, and interactions in ways that were unimaginable a few years ago. From text generation to answering questions, generative models have shown immense potential. However, these models—especially large language models (LLMs)—are not without their limitations. A key challenge is that they rely heavily on pre-trained data, which means their knowledge is frozen at the time of training. They cannot access real-time information, and they often fail to handle rare or niche queries that fall outside their pre-trained datasets.
These limitations are particularly problematic in environments where up-to-date or highly specific information is critical. For example, a financial analyst relying on an AI model might need access to the latest market data, or a customer support agent might need accurate technical documentation to resolve user queries. Traditional LLMs, which operate solely based on what they’ve learned, may struggle in these scenarios because they cannot access external data sources to provide timely and accurate answers.
Definition of Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is a solution to this challenge. It is a technique that enhances the capabilities of generative models by integrating real-time, external knowledge bases. Instead of generating content purely based on pre-trained data, RAG systems combine two key elements: a retriever, which fetches relevant information from external databases or documents, and a generator, which synthesizes this retrieved data with the model’s knowledge to produce an accurate and contextually relevant response.
In essence, RAG enhances the scope and depth of generative models by allowing them to augment their responses with real-world, up-to-date information. This method not only improves the quality of responses but also allows the AI to be more adaptable to specific domains or rapidly changing environments, making it ideal for businesses and functions where precision and timeliness are critical.
RAG represents a significant step forward for AI technology, providing a way to mitigate the inherent limitations of pre-trained models and making generative AI more robust, accurate, and applicable to a wider range of real-world use cases.
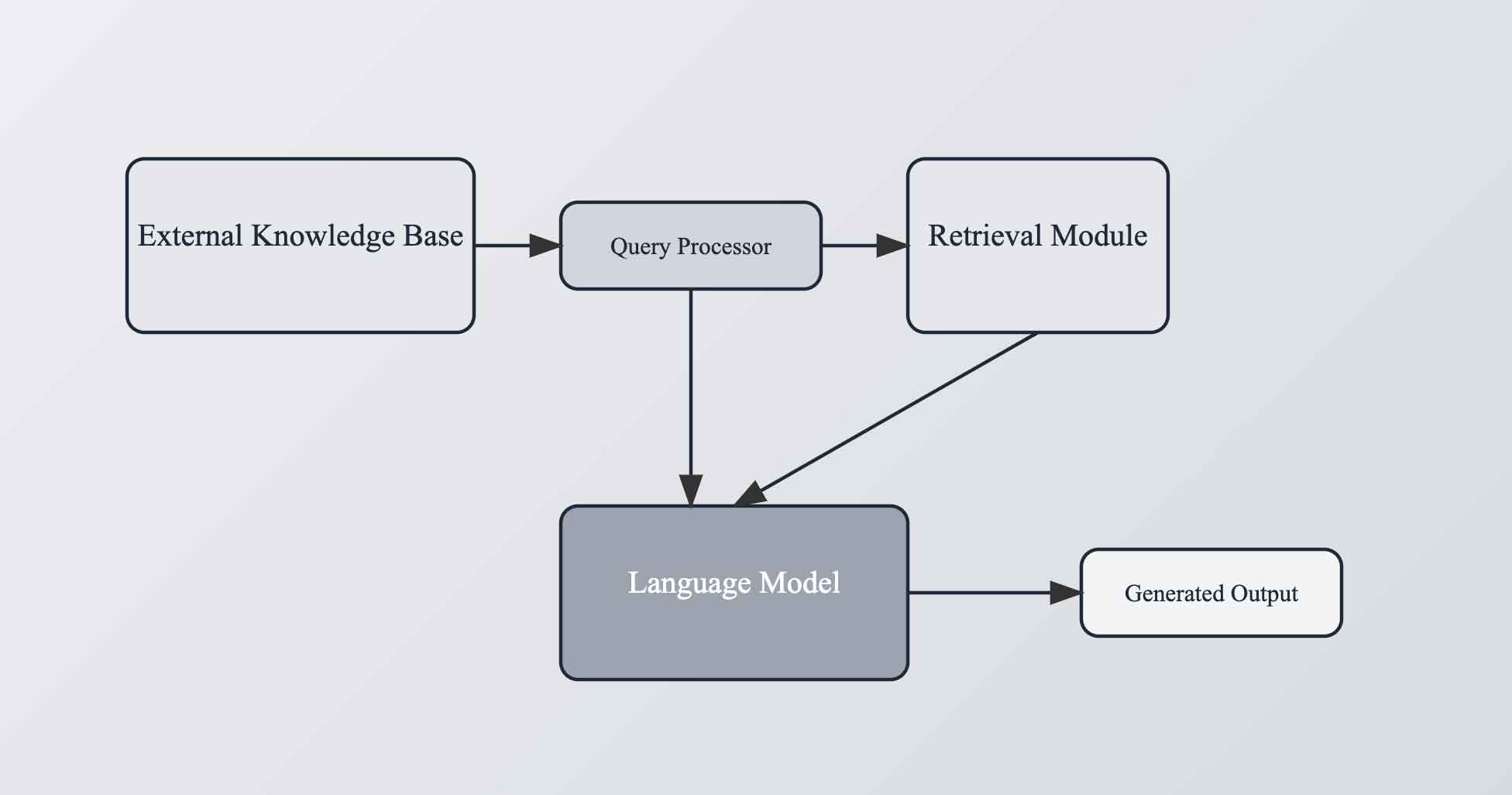
How Retrieval-Augmented Generation Works
Retrieval-Augmented Generation (RAG) combines two core components—retrievers and generators—to improve the accuracy and relevance of AI-generated content. This integration enables large language models (LLMs) to augment their internal knowledge by retrieving specific, up-to-date information from external sources.
Core Components of RAG
-
Retriever: The retriever is responsible for fetching relevant data from a knowledge base or external database based on the user’s input. This process involves a search mechanism that identifies the most relevant documents, articles, or data points that can enhance the AI’s output. The retriever uses methods like dense and sparse retrieval, often based on algorithms like BM25, BERT embeddings, or nearest-neighbor searches to locate the most relevant information.
The retriever acts as the bridge between the generative model and the external data. It allows the model to access the latest information without needing to retrain the model frequently. For example, when handling a question about recent events or niche topics, the retriever looks through external sources and returns relevant documents, which the generator can use to produce a more informed and accurate response.
-
Generator: The generator is responsible for producing the final output, synthesizing the retrieved information with its own pre-trained knowledge. Typically, the generator is a large language model like GPT or BART. In the RAG setup, the generator processes both the original input and the retrieved data, ensuring that the generated text is enriched with real-time, accurate information.
This system allows the generator to go beyond its pre-trained limits. The retrieved data augments the generator’s response by filling in knowledge gaps, particularly in areas where the model’s pre-training is outdated or incomplete. By incorporating relevant external data into its output, the generator can produce content that is not only contextually appropriate but also factually accurate and up-to-date.
RAG Process Flow
The RAG process consists of a structured flow that integrates retrieval and generation, enhancing AI’s performance in tasks that require accuracy and relevance:
-
Input Query: The process begins when a user inputs a query or a prompt into the system.
-
Retrieval Stage: Based on this input, the retriever searches through external databases or knowledge stores for relevant information. This retrieval can be conducted using various methods such as dense retrieval (embedding models) or sparse retrieval (e.g., BM25). The most relevant data is returned to the model for further processing.
-
Combining Query and Retrieved Data: The retrieved data, alongside the original query, is sent to the generator. Depending on the architecture, this data can be integrated into the model’s input, used to augment intermediate layers, or even influence the final stages of output generation.
-
Content Generation: The generator processes the combined input (original query + retrieved information) and generates a response. This response is more accurate and relevant than what the model would have produced without the retrieval process. It can handle more specific or niche queries by leveraging the latest data from external sources.
By dividing the process into retrieval and generation stages, RAG enables more flexible and accurate outputs, particularly in dynamic environments where data is frequently updated or when handling specialized topics. This hybrid approach is increasingly adopted in industries like healthcare, customer service, and finance to provide precise, real-time answers.
Advantages of Retrieval-Augmented Generation (RAG)
Increased Accuracy and Relevance
One of the most significant advantages of Retrieval-Augmented Generation (RAG) is its ability to enhance the accuracy and relevance of generated content. Traditional large language models (LLMs) rely solely on pre-trained data, which limits their ability to provide up-to-date or highly specialized information. RAG, however, allows these models to fetch real-time information from external knowledge bases or databases, ensuring that the generated output is both accurate and contextually relevant.
By incorporating external sources of information, RAG enables generative models to overcome one of their primary limitations: static knowledge. Whether handling questions related to niche domains or offering the latest information, RAG ensures that the model's output is grounded in current and reliable data. This significantly reduces the risks of misinformation and helps maintain the trustworthiness of AI systems across various applications.
Adaptability Across Functions
Another key strength of RAG lies in its adaptability across various business functions. Unlike traditional models, which may require frequent retraining or fine-tuning to handle different tasks, RAG is flexible enough to apply to different domains without constant updates. For example, RAG can be integrated into customer service systems, allowing AI-powered chatbots to retrieve and deliver real-time responses from internal knowledge bases, technical documentation, or product manuals.
Similarly, in decision support functions, RAG can fetch critical data and insights from external sources, helping decision-makers access up-to-date information needed for accurate financial, operational, or strategic decisions. Additionally, in content creation workflows, RAG can assist with generating personalized marketing materials, legal documents, or reports, all while ensuring that the information is timely and relevant to the user’s needs.
This adaptability eliminates the need for models to be retrained constantly for new functions, making RAG an efficient solution across various sectors, from healthcare and finance to retail and education.
Efficient Use of Resources
RAG also optimizes resource usage by reducing the need for continuous model updates or fine-tuning. In traditional AI systems, keeping models updated with the latest data requires retraining, which is computationally expensive and time-consuming. However, RAG eliminates this need by directly accessing external databases or knowledge repositories.
Rather than frequently fine-tuning the entire model, RAG focuses on fetching the necessary information in real-time, allowing for faster and more efficient responses. This not only saves computational resources but also reduces the costs associated with maintaining and updating models in a production environment.
In summary, RAG's ability to increase accuracy, adapt across functions, and optimize resource usage makes it a valuable tool for businesses looking to leverage AI without the overhead associated with traditional model management. Its flexibility and efficiency make it a crucial innovation for improving both the relevance and practicality of AI applications in dynamic environments.
Applications of Retrieval-Augmented Generation (RAG) Focused on Functions
1. Knowledge Management
In many organizations, accessing and managing vast internal documents, manuals, and proprietary knowledge bases can be a challenge. RAG streamlines knowledge management by efficiently retrieving and utilizing the most relevant information based on user queries. This is particularly useful in training scenarios, where employees need fast and accurate access to company policies, procedures, or technical documentation. By integrating RAG into internal systems, businesses can improve the efficiency of knowledge retrieval, ensuring that employees spend less time searching for information and more time applying it in practical situations.
For instance, in a large organization, RAG can automatically pull up the latest procedural manual or guidelines based on an employee's specific question. This minimizes time wasted on searching and ensures that users always access the most up-to-date resources.
2. Real-Time Decision Support
Decision-making, especially in fast-paced environments like finance or healthcare, requires access to the most current and reliable data. RAG can significantly improve real-time decision support by fetching up-to-the-minute information from external and internal data sources. For example, in financial services, RAG can retrieve real-time market data, economic indicators, or company financials to assist analysts in making well-informed decisions.
In healthcare, RAG systems could integrate with medical databases to provide doctors with the latest research, treatment protocols, or patient-specific data, helping them make better clinical decisions.
3. Customer Service Enhancement
RAG has a powerful role in enhancing customer service functions. Customer support systems often rely on large, technical knowledge bases that contain product manuals, FAQs, or troubleshooting guides. By implementing RAG, businesses can retrieve the most relevant and specific information from these knowledge bases in response to customer queries.
For example, if a customer reaches out for support with a technical product issue, a chatbot powered by RAG can quickly pull the relevant product manual section or troubleshooting guide, providing the customer with a fast and accurate resolution. This reduces the time to resolution and improves overall customer satisfaction.
4. Automated Content Creation
In the world of content creation, personalization and accuracy are critical. RAG can support the generation of tailored reports, legal documents, or marketing materials by combining internal data sets with external sources. This function is particularly useful for automating the creation of complex documents that require up-to-date information and personalization for specific audiences.
For instance, a marketing team can use RAG to pull real-time customer behavior data or market trends to automatically generate highly relevant content that resonates with the target audience. Similarly, legal professionals can use RAG to draft contracts or legal documents by retrieving the most current regulations or legal precedents relevant to the case.
5. Product Recommendations
Personalized product recommendations are a key driver of customer engagement in e-commerce. RAG enhances recommendation systems by fetching and analyzing relevant customer data, preferences, and current market trends to generate more precise suggestions. By integrating RAG, recommendation engines can tap into real-time data to offer personalized suggestions that align with the latest consumer behavior and preferences.
For example, an online retailer can use RAG to recommend products based on a customer’s previous purchases, browsing history, and even the latest trends in the market. This dynamic approach not only improves the accuracy of recommendations but also drives higher engagement and sales.
5. Key Techniques and Methodologies in RAG
Query-Based Retrieval
Query-based retrieval is a foundational technique within RAG systems, where the retriever retrieves relevant documents or data based on the user’s query. This retrieved content is then fed into the generative model as part of the input to refine its responses. The integration of external data helps the generator produce answers that are more precise, relevant, and grounded in real-world information. This method is widely used in text-based RAG applications, such as answering user questions or generating context-specific content from large corpora.
For example, in customer support scenarios, query-based retrieval systems can fetch information from knowledge bases, providing support agents with accurate, contextually relevant answers. This process involves searching external databases to gather information before it is passed into a generative model, enabling the model to provide responses that are informed by both pre-trained knowledge and up-to-date external data.
Reranking and Filtering
Reranking and filtering mechanisms play a crucial role in improving the retrieval quality within RAG systems. Once relevant documents are retrieved, these models re-rank the results to ensure the most pertinent information is used to generate the final output. This process minimizes the risk of irrelevant or less useful data affecting the quality of the response. Reranking can be achieved using machine learning models that assess the relevance of each retrieved document in relation to the query, improving the accuracy of the final response.
This methodology is particularly useful in automated content generation where the goal is to sift through large amounts of data and ensure that the most relevant pieces of information are used to produce content, reducing hallucinations or irrelevant outputs.
Integration of Latent Representations
In latent representation-based RAG, the retrieved data is not directly fed into the input sequence but instead integrated into the model at a deeper level as latent representations. These representations enhance the model’s ability to comprehend and generate complex responses. This technique often improves the depth of the content generated by enriching the generative model's internal understanding with additional retrieved information.
Latent representation methods are particularly valuable in complex tasks such as scientific content generation or legal document drafting, where both precision and contextual accuracy are paramount. For example, in applications like medical diagnosis, the RAG system can retrieve relevant research papers or historical medical data, integrate this information at a latent level, and generate well-informed, contextually grounded diagnoses or treatment suggestions.
These methodologies ensure that Retrieval-Augmented Generation provides highly accurate and contextually rich outputs, making RAG a versatile tool for industries requiring data-driven decision-making and content generation.
Challenges and Limitations of Retrieval-Augmented Generation (RAG)
Scalability
One of the significant challenges in deploying RAG at scale is the computational complexity involved in retrieving and processing large volumes of data in real time. In high-demand applications—such as large-scale enterprise systems or customer service platforms—retrieving data from vast external sources quickly can be computationally expensive. RAG systems rely on sophisticated retrieval models, which often involve searching through numerous documents and datasets, adding a considerable load to the system. As the volume of data increases, so does the requirement for memory, storage, and processing power. This scalability challenge is further compounded when handling diverse or multimodal datasets, as RAG systems must manage not only text but also images, videos, or other forms of data.
To address this, several techniques can be employed, such as optimizing retrieval methods, caching frequently accessed data, or implementing distributed retrieval architectures to spread the computational load. Another potential solution involves using hybrid architectures, as seen in some advanced models like NVIDIA's Jamba, which use a combination of expert layers to balance memory usage and reduce computational overhead.
Latency Issues
Latency is another critical concern in RAG systems, particularly when real-time responses are required. The process of querying external sources, retrieving data, and then passing it through the generative model introduces delays, which can affect user experience in time-sensitive applications. For instance, in customer service chatbots or real-time decision-making tools, even minor delays can lead to suboptimal user experiences or missed opportunities.
To mitigate latency, developers can implement various optimization strategies, such as parallelizing retrieval processes, using more efficient indexing methods, or pre-fetching and caching data that is frequently requested. Another approach is to prioritize the retrieval of smaller, more relevant data chunks instead of retrieving and processing larger volumes of data all at once. Advances in hardware acceleration, particularly using GPUs, have also helped reduce latency in RAG applications.
Privacy Concerns
Privacy is a major consideration when using RAG, especially in industries like healthcare and finance, where sensitive data is involved. The retrieval process often requires access to external databases, which can lead to the exposure of private or confidential information. For example, in healthcare, retrieving patient data from an external database could inadvertently expose sensitive medical records, leading to privacy violations and potential legal issues.
To mitigate these risks, companies need to implement strict access controls and encryption mechanisms to ensure that sensitive data is protected throughout the retrieval and generation process. Additionally, the retrieved information should be carefully filtered to avoid inadvertently leaking private data into generated outputs. Regulatory compliance, such as adhering to HIPAA in healthcare or GDPR in the European Union, is essential to ensuring the safe use of RAG systems in sensitive environments.
In summary, while RAG offers immense potential, it also presents challenges related to scalability, latency, and privacy. Addressing these limitations requires thoughtful implementation of technical optimizations, privacy safeguards, and compliance with industry regulations.
Future of Retrieval-Augmented Generation (RAG)
Improved Retrieval Mechanisms
As RAG technology evolves, one of the most critical areas for future improvement is the efficiency and accuracy of its retrieval mechanisms. Currently, retrieval models must sift through vast amounts of external data to identify the most relevant information for a given query, but there are limitations in both speed and precision. Future advancements will likely focus on creating more efficient algorithms that reduce computational overhead, allowing for faster retrieval without sacrificing accuracy.
One promising direction is the development of neural retrieval models that leverage deep learning techniques to better understand the context of queries and retrieved data. These models can go beyond keyword-based retrieval, interpreting the intent of the query and identifying semantically related documents, even if the specific keywords are not present. Additionally, hybrid retrieval methods that combine traditional information retrieval approaches with neural models could lead to a more optimized system capable of handling larger data volumes more effectively.
Further innovations could involve multi-hop retrieval systems, where multiple layers of data filtering and reranking ensure the best results are surfaced. These systems would not only pull in relevant documents but also track dependencies across multiple data points, providing more nuanced and contextually rich responses. As retrieval models become more advanced, the quality of the information fed into generative models will improve, allowing RAG to deliver increasingly accurate and context-aware outputs.
AI Agents and Multimodal Integration
Another exciting area of growth for RAG is the integration of multimodal data, such as images, video, and audio, alongside traditional text-based information. While current RAG systems primarily retrieve and generate text-based content, future systems will be able to handle more complex queries that require information from various modalities. For instance, a user might ask a RAG system to generate a report based on financial data, graphs, and visual presentations. To do this, the system would retrieve and integrate not only textual data but also relevant images and videos, creating a more comprehensive response.
Multimodal integration will be particularly impactful in industries like media, healthcare, and retail, where decision-makers need to analyze a wide range of data types. For example, in healthcare, a doctor could ask a RAG-powered system to retrieve both medical research papers and diagnostic images to assist in making an informed decision. Similarly, in retail, AI-driven virtual assistants could provide product recommendations by combining customer reviews, product images, and video demonstrations.
Moreover, the advancement of autonomous AI agents is closely tied to RAG's future. As AI agents become more self-sufficient, they will increasingly rely on RAG to retrieve accurate information across various contexts and modalities, making them more versatile in their problem-solving capabilities. For example, AI agents used in customer service could autonomously handle complex inquiries by retrieving knowledge from diverse data sources, such as video tutorials, manuals, and product specifications.
In conclusion, the future of RAG will involve improvements in retrieval efficiency, the integration of multimodal data, and the evolution of autonomous AI agents. These advancements will enable RAG to provide even more accurate, contextually rich, and actionable insights across a broader range of applications.
Summarize the Importance of RAG
Retrieval-Augmented Generation (RAG) represents a significant leap forward in enhancing the accuracy, relevance, and adaptability of generative AI models. By integrating real-time retrieval of external information, RAG overcomes the limitations of traditional models that rely solely on pre-trained data, providing more contextually accurate responses. Whether in customer service, decision support, or automated content creation, RAG allows systems to stay up to date, ensuring businesses can deliver precise and relevant information without constant retraining. The adaptability of RAG across various functions highlights its transformative potential, making it a key tool in industries ranging from finance to healthcare.
As businesses and developers seek to enhance operational efficiency and improve decision-making, RAG offers a powerful solution to enhance workflows, customer service, and personalized content creation. Companies are encouraged to explore and implement RAG systems to gain a competitive advantage by delivering more accurate, real-time insights, and fostering greater customer satisfaction. By integrating RAG into their AI ecosystems, organizations can streamline decision-making, boost productivity, and provide a more dynamic and responsive user experience.
References
- arXiv | Retrieval-Augmented Generation for AI-Generated Content: A Survey
- arXiv | Searching for Best Practices in Retrieval-Augmented Generation
- GitHub | What is Retrieval-Augmented Generation and What Does It Do for Generative AI?
- Dell | Unlocking GenAI Content Creation with the Power of RAG
- Oracle | Retrieval-Augmented Generation: Transforming Generative AI
- IBM | Enhancing AI with Retrieval-Augmented Generation
Please Note: Content may be periodically updated. For the most current and accurate information, consult official sources or industry experts.
Related keywords
- What is Artificial Intelligence (AI)?
- Explore Artificial Intelligence (AI): Learn about machine intelligence, its types, history, and impact on technology and society in this comprehensive introduction to AI.
- What is Large Language Model (LLM)?
- Large Language Model (LLM) is an advanced artificial intelligence system designed to process and generate human-like text.
- What is Prompt Engineering?
- Prompt Engineering is the key to unlocking AI's potential. Learn how to craft effective prompts for large language models (LLMs) and generate high-quality content, code, and more.