1. Introduction to Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) is a groundbreaking approach in artificial intelligence (AI) that unites information retrieval with natural language generation. While traditional large language models (LLMs) often rely on static training data—which can quickly become dated—RAG transcends this constraint by tapping into fresh, external knowledge sources. Consequently, it produces answers that are both fluid and factually grounded, proving especially valuable in domains such as health tech, legal consulting, and advanced customer support.
Throughout the development process of Giselle, our AI agent builder, we’ve seen firsthand how RAG can reinforce specialized AI agents for diverse workflows. Giselle lets you rapidly assemble and orchestrate these agents, each with its own focus. By incorporating RAG, these agents can dynamically pull the latest documents, APIs, and data repositories—ensuring that both input and output remain precise, timely, and closely tied to real insights. In doing so, they help developers deploy more robust solutions at a faster pace, while also minimizing the risk of outdated or inaccurate suggestions.
In essence, RAG augments an LLM’s generative capabilities with “on-demand” retrieval. The process breaks down into two main phases: retrieval and generation. First, the model scans a relevant knowledge base; then, it synthesizes that data with the original query to produce a cohesive response. This architecture helps cut down on “hallucinations”—incorrect or fabricated content often seen in standard LLMs—and significantly boosts factual accuracy.
Given how swiftly certain fields—like legal guidelines or medical research—can evolve, RAG’s ability to incorporate current information is a game changer. Plus, RAG inherently supports transparency; users can trace the sources of each response. At a time when explainability is a pressing topic in AI, that level of traceability is a considerable advantage. Below, we’ll explore how RAG operates, look at its key building blocks, and share a few methods for fine-tuning it in real deployments.
2. Core Components of RAG Systems
Retriever Mechanisms
The retriever is the beating heart of a RAG pipeline, charged with extracting relevant text or documents from external repositories. Internally, it typically translates a user query into a vector and compares it against stored embeddings to pinpoint the best matches. Techniques like BM25 (an evolved TF-IDF ranking approach) and Dense Passage Retrieval (DPR) are common tools here. Notably, DPR employs a bi-encoder system to capture nuanced semantic relationships, which can be a lifesaver when queries get complicated.
To further refine retrieval, many teams go beyond straightforward keyword searching. For instance, hierarchical indexes guide the model to the most critical sections of a large corpus, while Knowledge Graphs (KGs) illustrate connections among various entities, cutting down on irrelevant hits. Meanwhile, query rewriting or sub-query generation can help clarify user intent—especially if queries are vague or encompass multiple parts. In practice, we’ve found these strategies particularly useful when you need to break down a user’s complex question into more manageable sub-queries.
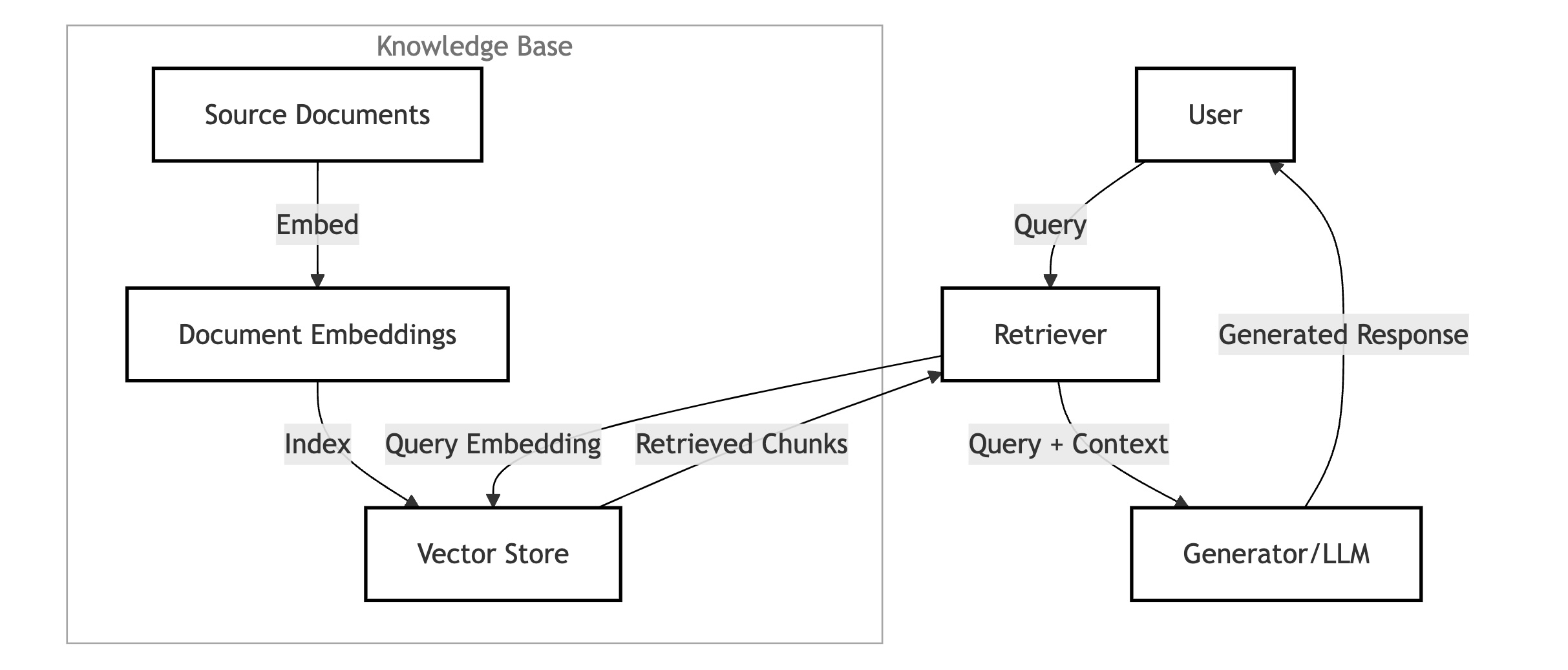
Generator Mechanisms
After the retriever does its part, the generator fuses the retrieved context with the user’s original prompt to form a coherent reply. Common LLMs for this step include T5 and BART: T5 excels at text-to-text tasks, while BART is adept at refining incomplete or noisy inputs. Regardless of the model, the main priority is to produce a response that aligns logically with the retrieved data.
On a technical note, it’s often helpful to employ re-ranking algorithms to emphasize the most relevant snippets, while context-compression methods prevent the model from being swamped by extraneous information. From our experience, too much unfiltered context can derail an LLM’s focus. Fine-tuning may further specialize the model for a given domain—like clinical documentation or enterprise resource management—and reinforcement learning can align its output with particular style guidelines or industry standards.
3. Augmentation Process in RAG
Iterative Retrieval
Rather than stopping at a single pass, iterative retrieval loops through retrieval and generation multiple times, gradually refining each step. This approach can lead to especially thorough answers—think of situations that demand multi-step reasoning or chain-of-thought solutions. However, it also risks confusion if the system surfaces conflicting information or fetches excessive, irrelevant content.
Frameworks like ITER-RETGEN balance “retrieval-enhanced generation” with “generation-enhanced retrieval,” making them well-suited for contexts like legal analysis, where each new detail in a query might point to an additional rule or clause. But be cautious not to overdo the iterations: too many cycles can produce cluttered contexts and diminish the overall quality of the result.
Recursive Retrieval
Closely related to iterative retrieval, recursive retrieval hones the query itself each time. After each retrieval pass, the system refines its query based on newly found data, zeroing in on what truly matters. Chain-of-thought strategies such as IRCoT can guide this evolution, while a “clarification tree” (ToC) systematically addresses ambiguities.
Some RAG setups begin with broad summaries of lengthy documents, then drill down step by step. This layered tactic is especially handy for graph-based data or multi-hop questions—like “Who mentored the inventor of X?”—often seen in academic research or genealogical investigations, where one answer naturally spawns the next question.
Adaptive Retrieval
Adaptive retrieval adopts a more flexible stance: the model decides, on the fly, whether another retrieval pass is warranted. If the system’s confidence in its current generation drops below a predefined threshold, it kicks off a new retrieval cycle. Tools like Self-RAG rely on “reflection tokens” or similar signals to trigger re-checks of external sources. (Experimental methods like FLARE have explored parallel concepts, but the references remain limited.)
From an efficiency standpoint, this can be highly valuable. Rather than retrieving for every request, the system only fetches data when it detects a knowledge gap. If it’s already confident, it skips retrieval entirely, saving computing resources and minimizing overhead for development teams.
4. Evaluation Metrics for RAG Systems
Retrieval Quality Metrics
Assessing retrieval performance is vital for ensuring the generator has solid groundwork. Common indicators include Hit Rate, Mean Reciprocal Rank (MRR), and Normalized Discounted Cumulative Gain (NDCG). Collectively, these metrics ask: Did the system find at least one relevant document (Hit Rate)? How quickly did it find the first correct result (MRR)? And how was the overall ranking quality (NDCG)?
Still, standard IR metrics tell only part of the story. It’s equally important to measure how well the retrieved context aligns with the user’s query (context relevance) and whether the system avoids contradictory or suspect material (noise robustness). Even small modifications to indexing or query expansion have been known to enhance retrieval quality significantly.
Generation Quality Metrics
Once you have your retrieved content, the final output’s coherence and factual accuracy become pivotal. BLEU and ROUGE compare generated text to reference examples, though many RAG use cases lack a single “ideal” answer. That’s where more qualitative checks enter the picture, such as confirming the output’s “faithfulness” to the retrieved information, ensuring “relevance” to the prompt, and verifying “non-harmfulness.”
Additional aspects include negative rejection (can the system politely say “I don’t know” if data is lacking?), multi-document integration (does it blend multiple sources effectively?), and counterfactual robustness (can it spot and dodge misinformation embedded in retrieved passages?). Taken together, these metrics aim to confirm that the output is both well-informed and responsibly generated—a particularly salient concern in healthcare or finance.
5. RAG vs. Fine-Tuning
RAG vs. Fine-Tuning: Key Differences
When it comes to tailoring LLMs, two prominent strategies stand out: Retrieval-Augmented Generation (RAG) and fine-tuning. RAG consults external sources at inference time, whereas fine-tuning alters a model’s internal parameters using specialized datasets. The choice often hinges on how rapidly your data environment changes and how much computational effort you can devote to training.
For domains in constant flux—like live market data, cutting-edge research, or dynamic online communities—RAG’s real-time retrieval can be invaluable. That said, repeated retrieval ramps up computational costs. Fine-tuning, on the other hand, can yield quicker inference once a model is fully trained, but it requires ongoing retraining to stay relevant. Many developers end up adopting a hybrid approach that taps into both RAG and fine-tuning, especially if they need domain-specific tone and real-time updates simultaneously.
Advantages and Disadvantages of RAG
Because RAG pulls data from external sources, it’s ideal for fast-changing environments and offers transparency into where facts originate. However, that extra retrieval step can slow things down, and external data sources can be biased or low quality. Fine-tuning, for its part, is well-suited to stable contexts, with fewer moving parts at inference, but it doesn’t adapt easily to brand-new knowledge and can become obsolete quickly.
Studies often reveal that RAG outperforms unsupervised fine-tuning on knowledge-heavy tasks, especially when dealing with newly emerging information that wasn’t part of the original training corpus. Meanwhile, fine-tuning shines at honing a model’s “voice” yet struggles to incorporate facts it never saw during training. Ultimately, it comes down to how frequently your data evolves and how critical real-time accuracy is to your needs.
6. Challenges and Limitations of RAG
Robustness to Noise and Misinformation
Like any system that relies on external data, RAG can be vulnerable to “garbage in, garbage out”—particularly if the sources are contradictory or biased. If the retriever unearths flawed information, the model may propagate it. Some observers even argue that “misinformation is worse than no information at all.” Yet in some instances, a bit of extra data—provided it’s effectively filtered—can enrich coverage.
Bias detection in retrieval has thus become a growing priority. When certain sources consistently skew toward a particular viewpoint, the system must either account for that bias or exclude them outright. Striking a balance between maximum recall and reliability can be tricky—especially in domains where you can’t afford to be wrong.
Addressing Context Limitations
Another challenge lies in the limited context window that even advanced LLMs have. While context sizes keep expanding, they’re not infinite. Piling on too many documents can overload the model and cause it to skip or de-emphasize crucial middle segments.
In specialized areas like healthcare or law, regular updates to best practices or regulations are non-negotiable. This often forces teams to repeatedly fine-tune or re-index their models. Formal benchmarks for RAG in niche sectors can also be sparse, so teams sometimes create their own tests or rely on domain experts to approve system changes, as is common in medical AI.
7. RAG Ecosystem and Tools
In tandem with the evolution of retrieval algorithms and LLM frameworks, the RAG ecosystem has gained considerable traction. LangChain and LlamaIndex, for instance, streamline workflows for data handling, retrieval, and text generation. Low-code platforms like Flowise AI further lower the barrier to experimentation by offering drag-and-drop interfaces, so even non-specialists can dabble in RAG.
# RAG Demo: Simple Retrieval + Generation with LangChain
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
# 1. Prepare a small set of sample documents
docs = [
"Document about RAG: RAG stands for Retrieval-Augmented Generation. It helps LLMs fetch external data...",
"Another doc about LLMs and the importance of external knowledge retrieval..."
]
# 2. Define the embeddings (vector representation of text)
embeddings = OpenAIEmbeddings(openai_api_key="YOUR_OPENAI_API_KEY")
# 3. Split each document into text chunks
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
split_texts = []
for doc in docs:
split_texts.extend(text_splitter.split_text(doc))
# 4. Build a vector store from the chunks
vectorstore = FAISS.from_texts(split_texts, embeddings)
# 5. Create a RetrievalQA chain
retrieval_qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(openai_api_key="YOUR_OPENAI_API_KEY", temperature=0),
chain_type="stuff",
retriever=vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 1}
)
)
# 6. Ask a user query via the RAG pipeline
query = "What is RAG and how does it benefit LLMs?"
response = retrieval_qa.run(query)
print(f"Question: {query}")
print(f"Answer: {response}")
Beyond up-and-coming AI vendors, well-established tech companies are also exploring RAG solutions. Weaviate provides an open-source vector database and search platform—often used for personal assistant applications—while Amazon Kendra specializes in enterprise search across myriad data silos. With so many RAG offerings on the market, teams can choose everything from small prototypes to fully scaled production pipelines.
Meanwhile, as next-generation LLMs extend their context windows—some are rumored to support considerably more tokens—RAG can harness even larger text snippets, making retrieval more adaptive. And though a fully integrated, one-stop “RAG platform” hasn’t yet emerged, it feels like we’re inching ever closer to that horizon, particularly as specialized solutions and production-ready variants continue to mature.
8. Future Research Directions in RAG
Multimodal Integration
Multimodal RAG merges text, images, audio, or even video into a single framework. Think of a diagnostic system that analyzes both written patient notes and X-ray images, or an educational platform that fuses lecture transcripts with annotated visuals. Achieving this requires:
- Advanced retrieval techniques that handle diverse data types and formats.
- Adaptable generator architectures capable of reconciling multiple streams of input.
Such innovations could transform fields like healthcare, education, and content creation by allowing AI to interpret and produce information across a variety of formats.
Hybrid Approaches
RAG can also be paired with fine-tuning or smaller, specialized models in various ways:
- Sequential or Joint Training: First train an LLM, then integrate RAG, or vice versa.
- Small Language Models (SLMs): Use lightweight models to validate retrieval. If the system flags questionable data, it can prompt another retrieval attempt.
- Knowledge Distillation & Reinforcement Learning: Optimize RAG for certain tasks using advanced techniques that pass knowledge from larger models to smaller ones or refine the process with iterative feedback.
The goal is to harness the best of retrieval and parameter fine-tuning, delivering systems that are more accurate, adaptive, and context-aware.
Robustness and Adaptability
Because real data evolves, RAG models must stay accurate and bias-free:
- Lifelong Learning: Keep updating with new information without losing existing knowledge.
- Domain Adaptation: Reduce the frequency of costly retraining cycles in specialized fields, like law or medicine.
- Cross-Lingual Retrieval: Expand RAG’s reach to multiple languages for broader, global coverage.
Ultimately, researchers aim to build RAG setups that can quickly adapt to new data, maintain factual rigor, and operate reliably in high-stakes environments.
9. RAG and Giselle
Within Giselle—a workflow builder for coordinating multiple LLMs and data sources—RAG can offer substantial advantages. Giselle’s node-based interface already streamlines the development of specialized AI Agents, but the true impact emerges when you combine generation with retrieval to ensure everything stays correct and up to date.
Picture an AI agent tasked with drafting a Product Requirement Document (PRD). With RAG, it can reference the latest market trends, product specifications, or even relevant code fragments from a GitHub repo before putting together a draft. Meanwhile, another agent might handle code reviews, fetching best practices and security guidelines tailored to frameworks like React or Rust. Together, they maintain a consistent, informed approach that reduces the risk of outdated or incomplete recommendations.
Finally, Giselle’s multi-agent orchestration stands to gain a lot from RAG’s flexibility. Even if different agents handle tasks like compliance checks, technical documentation, or user research, they can all share a unified knowledge pool. In short, RAG helps them converge on a single source of truth, fostering a more dependable, AI-driven system capable of tackling even complex projects with fewer blind spots and less friction.
Try Giselle's Open Source: Build AI Agents Visually
Effortlessly build AI workflows with our intuitive, node-based playground. Deploy agents ready for production with ease.